Each P5 EC2 instances has
- eight NVIDIA H100 GPUs capable of 16 petaFLOPs of mixed-precision performance
- 640 GB of high-bandwidth memory, 80GB in each GPU
- 3,200 Gbps networking connectivity (8x more than the previous generation)
The increased performance of P5 instances accelerates the time-to-train machine learning (ML) models by up to 6x (reducing training time from days to hours), and the additional GPU memory helps customers train larger, more complex models.
P5 instances are expected to lower the cost to train ML models by up to 40% over the previous generation, providing customers greater efficiency over less flexible cloud offerings or expensive on-premises systems.
Nvidia H100 GPU overview and data sheet – https://resources.nvidia.com/en-us-tensor-core/gtc22-whitepaper-hopper
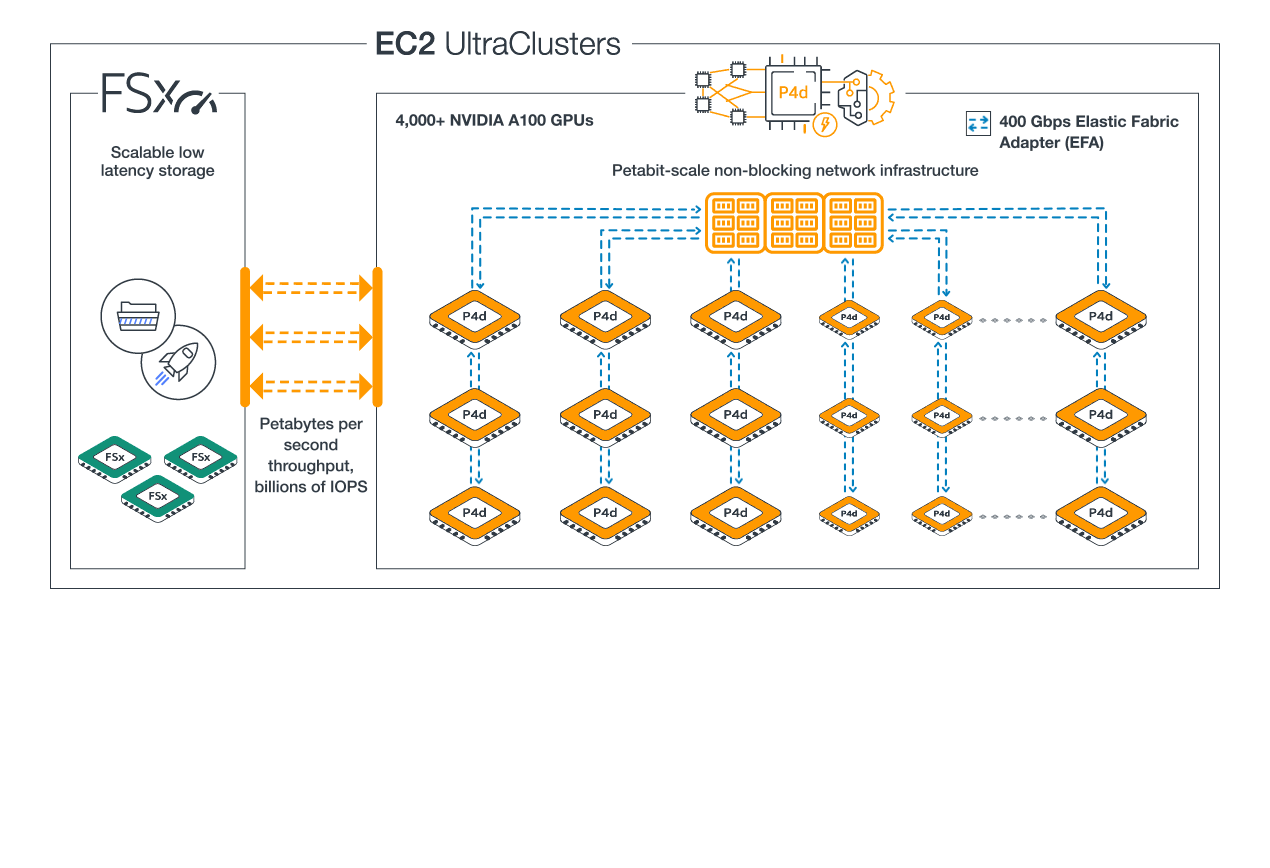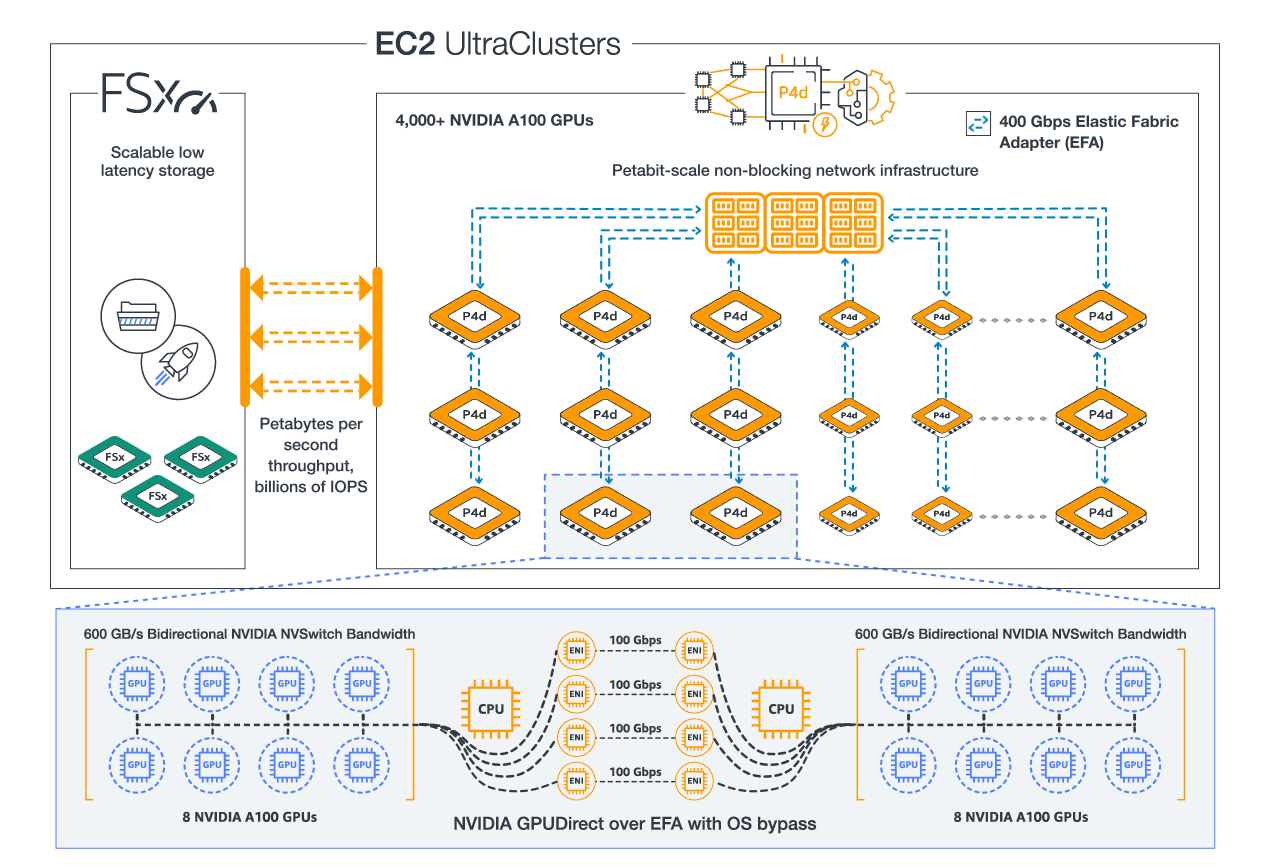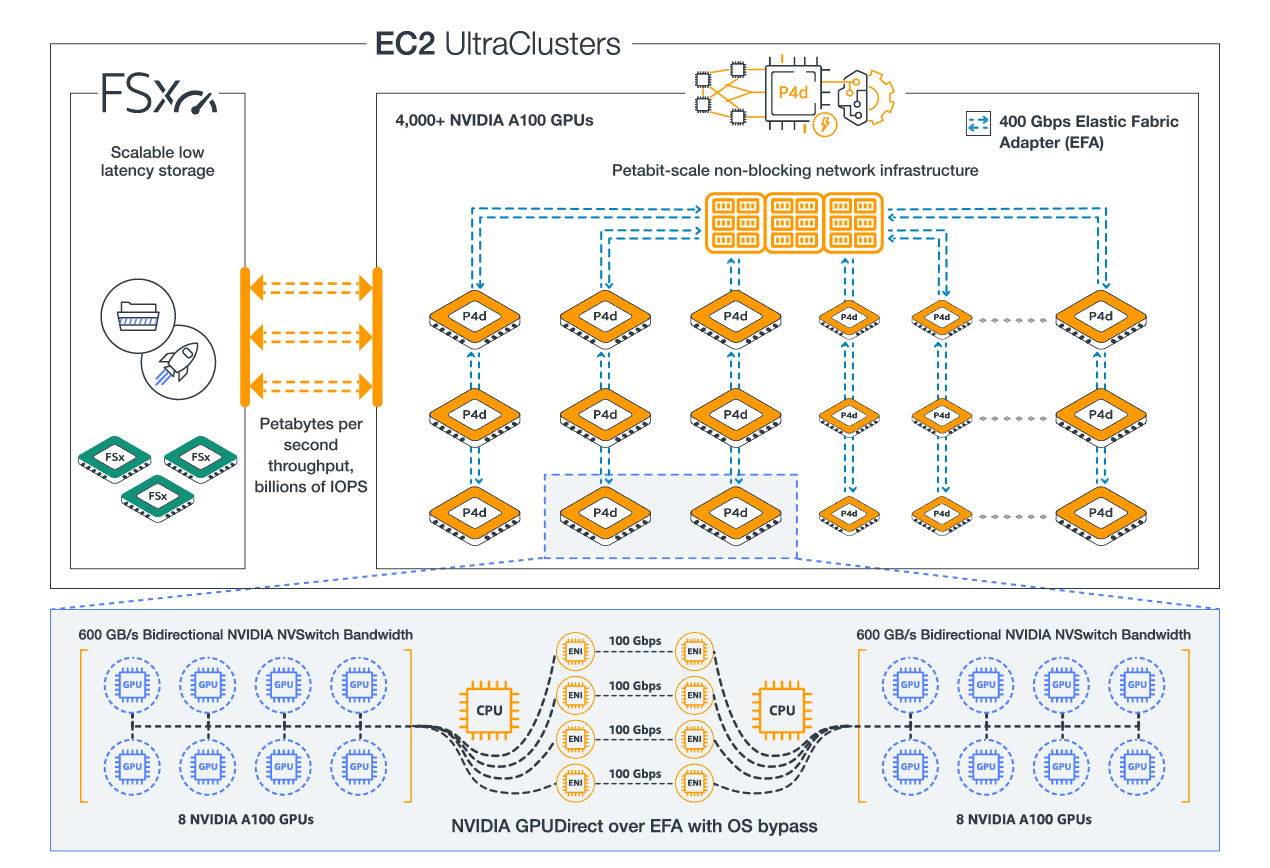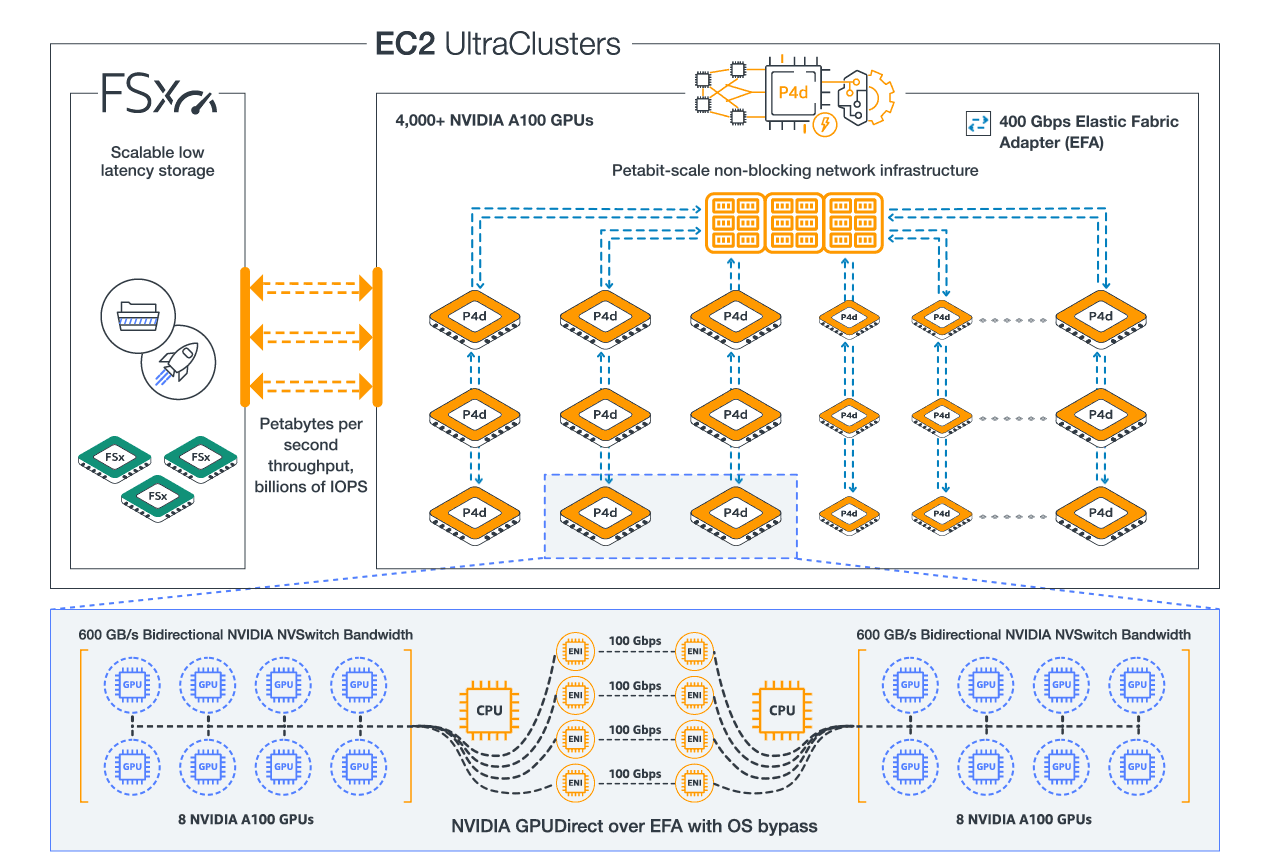
Diagram of P4d UltraClusters
P4d consists of 8 A100 GPUs, with 40GB GPU Memory each
P4de consists of 8 A100 80GB GPUs, with 80GB GPU memory each
Nvidia blog on HGX baseboard supporting 8 A100 GPUs – https://developer.nvidia.com/blog/introducing-hgx-a100-most-powerful-accelerated-server-platform-for-ai-hpc/
A100 80GB data sheet – https://www.nvidia.com/en-us/data-center/a100/
MIG support in A100 – https://developer.nvidia.com/blog/getting-the-most-out-of-the-a100-gpu-with-multi-instance-gpu/ and MIG user guide – https://docs.nvidia.com/datacenter/tesla/mig-user-guide
MIG support in AWS EC2 instance type P4d and in AWS EKS – https://developer.nvidia.com/blog/amazon-elastic-kubernetes-services-now-offers-native-support-for-nvidia-a100-multi-instance-gpus/
GCP A2 adds 16 A100 GPUs to a node – https://cloud.google.com/blog/products/compute/announcing-google-cloud-a2-vm-family-based-on-nvidia-a100-gpu
https://cloud.google.com/blog/products/containers-kubernetes/gke-now-supports-multi-instance-gpus
Running more pods/gpu on EKS with MIG – https://medium.com/itnext/run-more-pods-per-gpu-with-nvidia-multi-instance-gpu-d4f7fb07c9b5
Nvidia Embraces The CPU World With “Grace” Arm Server Chip
