A Graphics Processing Unit (GPU) allows multiple hardware processors to act in parallel on a single array of data, allowing a divide and conquer approach to large computational tasks such as video frame rendering, image recognition, and various types of mathematical analysis including convolutional neural networks (CNNs). The GPU is typically placed on a larger chip which includes CPU(s) to direct data to the GPUs. This trend is making supercomputing tasks much cheaper than before .
Tesla_v100 is a System on Chip (SoC) which contains the Volta GPU which contains TensorCores, designed specifically for accelerating deep learning, by accelerating the matrix operation D = A*B+C, each input being a 4×4 matrix. More on Volta at https://devblogs.nvidia.com/parallelforall/inside-volta/ . It is helpful to read the architecture of the previous Pascal P100 chip which contains the GP100 GPU, described here – http://wccftech.com/nvidia-pascal-specs/ . Background on why NVidia builds chips this way (SIMD < SIMT < SMT) is here – http://yosefk.com/blog/simd-simt-smt-parallelism-in-nvidia-gpus.html .
Volta GV100 GPU = 6 GraphicsProcessingClusters x 7 TextureProcessingCluster/GraphicsProcessingCluster x 2 StreamingMultiprocessor/TextureProcessingCluster x (64 FP32Units +64 INT32Units + 32 FP64Units +8 TensorCoreUnits +4 TextureUnits)
The FP32 cores are referred to as CUDA cores, which means 84×64 = 5376 CUDA cores per Volta GPU. The Tesla V100 which is the first product (SoC) to use the Volta GPU uses only 80 of the 84 SMs, or 80×64=5120 cores. The frequency of the chip is 1.455Ghz. The Fused-Multiply-Add (FMA) instruction does a multiplication and addition in a single instruction (a*b+c), resulting in 2 FP operations per instruction, giving a FLOPS of 1.455*2*5120=14.9 Tera FLOPs due to the CUDA cores alone. The TensorCores do a 3d Multiply-and-Add with 7x4x4+4×4=128 FP ops/cycle, for a total of 1.455*80*8*128 = 120TFLOPS for deep learning apps.
3D matrix multiplication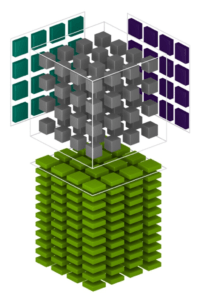
The Volta GPU uses a 12nm manufacturing process, down from 16nm for Pascal. For comparison the Jetson TX1 claims 1TFLOPS and the TX2 twice that (or same performance with half the power of TX1). The VOLTA will be available on Azure, AWS and platforms such as Facebook. Several applications in Amazon. MS Cognitive toolkit will use it.
For comparison, the Google TPU runs at 700Mhz, and is manufactured with a 28nm process. Instead of FP operations, it uses quantization to integers and a systolic array approach to minimize the watts per matrix multiplication, and optimizes for neural network calculations instead of more general GPU operations. The TPU uses a design based on an array of 256×256 multiply-accumulate (MAC) units, resulting in 92 Tera Integer ops/second.
Given that NVidia is targeting additional use cases such as computer vision and graphics rendering along with neural network use cases, this approach would not make sense.
Miscellaneous conference notes:
Nvidia DGX-1. “Personal Supercomputer” for $69000 was announced. This contains eight Tesla_v100 accelerators connected over NVLink.
Tesla. FHHL, Full Height, Half Length. Inferencing. Volta is ideal for inferencing, not just training. Also for data centers. Power and cooling use 40% of the datacenter.
As AI data floods the data centers, Volta can replace 500 CPUswith 33 GPUs.
Nvidia GPU cloud. Download the container of your choice. First hybrid deep learning cloud network. Nvidia.com/cloud . Private beta extended to gtc attendees.
Containerization with GPU support. Host has the right NVidia driver. Docker from GPU cloud adapts to the host version. Single docker. Nvidiadocker tool to initialize the drivers.
Moores law comes to an end. Need AI at the edge, far from the data center. Need it to be compact and cheap.
Jetson board had a Tegra SoC chip which has 6cpus and a Pascal GPU.
AWS Device Shadows vs GE Digital Twins. Different focus. Availabaility+connectivity vs operational efficiency. Manufacturing perspective vs operational perspective. Locomotive may be simulated when disconnected .
DeepInstinct analysed malware data using convolutional neural networks on GPUs, to better detect malware and its variations.
Omni.ai – deep learning for time series data to detect anomalous conditions on sensors on the field such as pressure in a gas pipeline.
GANS applications to various problems – will be refined in next few years.
GeForce 960 video card. Older but popular card for gamers, used the Maxwell GPU, which is older than Pascal GPU.
Cooperative Groups in Cuda9. More on Cuda9.
