An Agent is in an Environment. a) Agent reads Input (State) from Environment. b) Agent produces Output (Action) that affects its State relative to Environment c) Agent receives Reward (or feedback) for the Output produced. With the reward/feedback it receives it learns to produce better Output for given Input. The map that captures the set of available Actions, consequent Rewards and subsequent States for each State is called the Policy. This is a brief look at RL from the perspective of control theory. This map is actually a map of probabilities of the state transitions and another way of looking at RL is as a Markov Decision Process.
Where do neural networks come in ?
Optimal control theory considers control of a dynamical system such that an objective function is optimized (with applications including stability of rockets, helicopters). In optimal control theory, Pontryagin’s principle says: a necessary condition for solving the optimal control problem is that the control input should be chosen to minimize the control Hamiltonian. This “control Hamiltonian” is inspired by the classical Hamiltonian and the principle of least action. The goal is to find an optimal control policy function u∗(t) and, with it, an optimal trajectory of the state variable x∗(t) which by Pontryagin’s maximum principle are the arguments that maximize the Hamiltonian.
Derivatives are needed for the continuous optimizations. In which direction and by what amount should the weights be adjusted to reduce the observed error in the output ? What is the structure of the input to output map to begin with ? Deep learning models are capable of performing continuous linear and non-linear transformations, which in turn can compute derivatives and integrals. They can be trained automatically using real-world inputs, outputs and feedback. So a neural network can provide a system for sophisticated feedback-based non-linear optimization of the map from Input space to Output space. The structure of the network is being learned empirically. For example this 2017 paper uses 8 layers (5 convolutional and 3 fully connected) to train a neural network on the ImageNet database.
The above could be accomplished by a feedforward neural network that is trained with a feedback (reward). Additionally a recurrent neural network could encode a memory into the system by making reference to previous states (likely with higher training and convergence costs).
Model-free reinforcement learning does not explicitly learn a model of the environment.
The optimal action-value function obeys an identity known as the Bellman equation. If the quality of the action selection were known for every state then the optimal strategy at every state is to select the action that maximizes the (local) quality. [ Playing Atari with Deep Reinforcement Learning, https://arxiv.org/pdf/1312.5602.pdf ]
Manifestations of RL: Udacity self-driving course – lane detection. Karpathy’s RL blog post has an explanation of a network structure that can produce policies in a malleable manner, called policy gradients.
Practical issues in Reinforcement Learning –
Raw inputs vs model inputs: There is the problem of mapping inputs from real-world to the actual inputs to a computer algorithm. Volume/quality of information – high vs low requirement.
Exploitation vs exploration dilemma: https://en.wikipedia.org/wiki/Multi-armed_bandit. Simple exploration methods are the most practical. With probability ε, exploration is chosen, and the action is chosen uniformly at random. With probability 1 − ε, exploitation is chosen, and the agent chooses the action that it believes has the best long-term effect (ties between actions are broken uniformly at random). ε is usually a fixed parameter but can be adjusted either according to a schedule (making the agent explore progressively less), or adaptively based on heuristics.
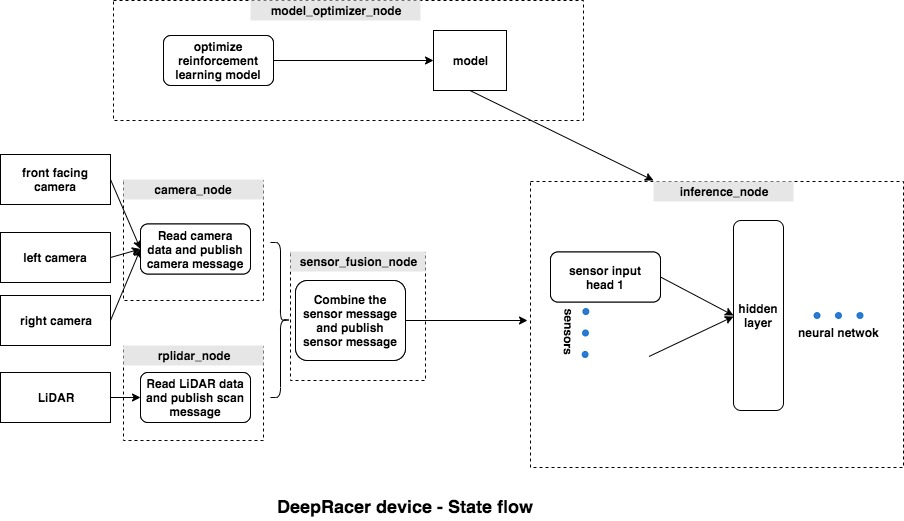
AWS DeepRacer. Allows exploration of RL. Simplifies the mapping of camera input to computer input, so one can focus more on the reward function and deep learning aspects. The car has a set of possible actions (change heading, change speed). The RL task is to predict the actions based on the inputs.
What are some of the strategies applied to winning DeepRacer ?
- Implementation of the pure pursuit tracking problem, used by Scott Pletcher.
- Explicit reward based on proximity, distance and speed by Daniel Gonzalez and team in https://towardsdatascience.com/an-advanced-guide-to-aws-deepracer-2b462c37eea
- https://medium.com/dbs-tech-blog/an-introduction-to-aws-deepracer-from-a-2020-world-championship-finalist-3a63b5c8d8aa Fully autonomous vs Semi-autonomous. Input parameters for the reward function. Log analysis for optimizing the models.
- Faster training vs slower training – https://falktan.medium.com/aws-deepracer-how-to-train-a-model-in-15-minutes-a07ab77fb793 (PPO takes full lap to learn, line of sight learns in sub-lap distances).
- Soft-actor-critic algorithm. SAC demystified – https://towardsdatascience.com/soft-actor-critic-demystified-b8427df61665 . SAC works to increase entropy (to encourage exploration) and not just maximize rewards.
Reward function input parameters – https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-reward-function-input.html
On-policy vs off-policy methods: This has to do with the policies used for exploration and exploitation. If the same policy is used for both, it’s called on-policy. If there are two different policies, one for exploration and the other for exploitation it is called an off-policy method. PPO is on-policy, SAC is off-policy. A good read on policy optimization – https://spinningup.openai.com/en/latest/spinningup/rl_intro3.html and one on the Actor-Critic model – https://huggingface.co/learn/deep-rl-course/unit6/advantage-actor-critic .
Original paper – Proximal Policy Optimization Algorithms is at https://arxiv.org/pdf/1707.06347.pdf .

PPO – Actor Critic Network.
“DeepRacer: Educational Autonomous Racing Platform for Experimentation with Sim2Real Reinforcement Learning” – https://arxiv.org/pdf/1911.01562.pdf
DeepRacer uses RLLib which brings forth a key idea of encapsulating parallelism in the context of AI applications, as described in RLlib: Abstractions for Distributed Reinforcement Learning. RLLib is part of Ray, described in Ray: A Distributed Framework for Emerging AI Applications . Encapsulating parallelism means that individual components specify their own internal parallelism and resources requirements and can be used by other components without any knowledge of these. This allows a larger system to be built from modular components.
OpenAI Gym offers a suite of environments for developing and comparing RL algorithms. It emphasizes environments over agents, complexity over performance, knowledge sharing over competition. https://github.com/openai/gym , Open AI Gym paper. Here’s a code snippet from this paper of how they see an agent interact with the environments over 100 steps of a training episode.
ob0 = env.reset() # sample environment state, return first observation
a0 = agent.act(ob0) # agent chooses first action
ob1, rew0, done0, info0 = env.step(a0) # environment returns observation,
# reward, and boolean flag indicating if the episode is complete.
a1 = agent.act(ob1)
ob2, rew1, done1, info1 = env.step(a1)
...
a99 = agent.act(o99)
ob100, rew99, done99, info2 = env.step(a99)
# done99 == True => terminalRL is not a fit for every problem. Alternative approaches with better explainability and determinism include behavior trees, vectorization/VectorNet, …
DeepMind says reinforcement learning is ‘enough’ to reach general AI – https://news.ycombinator.com/item?id=27456315
Richard Sutton and Andrew Barto’s book on RL: An introduction.
This paper explores incorporating Attention mechanism with Reinforcement learning – Reinforcement Learning with Attention that Works: A Self-Supervised Approach. A video review of the ‘Attention is all you need’ is here, the idea being to replace an RNN with a mechanism to selectivity track a few relevant things.
Multi agent Deep Deterministic Policy Gradients – cooperation between agents. https://www.youtube.com/watch?v=tZTQ6S9PfkE. Agents learn a centralized critic based on the observations and actions of all agents. https://arxiv.org/pdf/1706.02275.pdf .
Multi-vehicle RL for multi-lane driving. https://arxiv.org/pdf/1911.11699v1.pdf
