AlphaFold is a deep learning model developed by DeepMind that predicts protein structure. It uses a two-step process: First, it generates a representation of the protein’s amino acid sequence. Then, it refines this representation to predict the 3D structure of the protein. The model is trained on a large database of known protein structures and uses a convolutional neural network (CNN) to make these predictions. It leverages the concept of attention mechanisms to incorporate information from multiple parts of the protein sequence during the prediction process. It combines advanced machine learning techniques with protein structure data to make accurate predictions about protein folding.
Attention mechanisms are a key component of AlphaFold and play a crucial role in capturing dependencies between different parts of a protein sequence. It was interesting to deconstruct attention in a non-text use case – the median human protein is made of only 375 amino acids and most proteins are encoded with less than a 1000 amino acids. So to understand the attention mechanism, let’s break it down step by step using AlphaFold as the reference use case.
- Embedding the Protein Sequence:
AlphaFold starts by embedding the amino acid sequence of a protein into a numerical representation. Each amino acid is represented as a vector, and these vectors are combined to form the input sequence matrix, X ∈ ℝ^(L×D), where L is the length of the sequence and D is the dimensionality of each amino acid vector. - Creating Query, Key, and Value Matrices:
AlphaFold then generates three matrices – Query (Q), Key (K), and Value (V) – by linearly transforming the input sequence matrix X. This transformation is performed using learnable weight matrices WQ, WK, and WV. The resulting matrices are Q = XWQ, K = XWK, and V = XWV, each having dimensions of L×D. - Calculating Attention Weights:
The attention mechanism computes the similarity between each query vector and key vector by taking their dot products. This similarity is scaled by a factor of √(D), and a softmax function is applied to obtain attention weights. The attention weights determine how much each key contributes to the final output. Let’s denote the attention weights matrix as A ∈ ℝ^(L×L), where each element A_ij represents the attention weight between the i-th query and j-th key. The attention weights are calculated as follows: A_ij = softmax((Q_i ⋅ K_j) / √(D)) Here, Q_i represents the i-th row of the Query matrix, and K_j represents the j-th row of the Key matrix. - Weighted Sum of Values:
The final step is to compute the weighted sum of the Value matrix using the attention weights. This is done by taking the matrix multiplication of attention weights A and the Value matrix V. The resulting matrix C, representing the context or attended representation, is given by: C = AV The context matrix C has dimensions of L×D, where each row represents a weighted sum of the Value vectors based on the attention weights.
Attention mechanisms in AlphaFold allow the model to capture the relationships and dependencies between different parts of the protein sequence. By assigning attention weights to relevant amino acids, the model can focus on important regions during the prediction process, enabling accurate protein structure predictions.
The dimensions of the matrices involved are as follows:
- Input Sequence Matrix (X): X ∈ ℝ^(L×D), where L is the length of the protein sequence and D is the dimensionality of each amino acid vector.
- Query Matrix (Q): Q ∈ ℝ^(L×D), same as the dimensions of X.
- Key Matrix (K): K ∈ ℝ^(L×D), same as the dimensions of X.
- Value Matrix (V): V ∈ ℝ^(L×D), same as the dimensions of X.
- Attention Weights Matrix (A): A ∈ ℝ^(L×L), where each element A_ij represents the attention weight between the i-th query and j-th key.
- Context Matrix (C): C ∈ ℝ^(L×D), same as the dimensions of X.
So the matrices Q, K, V, X, and C have dimensions L×D, where L represents the length of the protein sequence and D represents the dimensionality of the amino acid vectors. The attention weights matrix A has dimensions L×L, capturing the attention weights between each query and key pair.
OpenFold is a pytorch based reproduction of alphafold , a comparison is used in https://wandb.ai/telidavies/ml-news/reports/OpenFold-A-PyTorch-Reproduction-Of-DeepMind-s-AlphaFold–VmlldzoyMjE3MjI5
What are amino acids ? Amino acids are organic compounds that serve as the building blocks of proteins. They contain an amino group (-NH2) and a carboxyl group (-COOH) attached to a central carbon atom, along with a specific side chain (R-group). The side chain varies among different amino acids, giving them unique properties.
There are 20 standard amino acids that are commonly found in proteins. Each amino acid has a unique structure and properties, determined by its specific side chain. Some examples include glycine, alanine, valine, leucine, isoleucine, serine, threonine, cysteine, methionine, aspartic acid, glutamic acid, lysine, arginine, histidine, phenylalanine, tyrosine, tryptophan, asparagine, glutamine, and proline.
Amino acids encode proteins through a process called translation. The genetic information stored in DNA is transcribed into messenger RNA (mRNA). The mRNA is then read by ribosomes, which assemble amino acids in a specific sequence according to the instructions provided by the mRNA. This sequence of amino acids forms a polypeptide chain, which then folds into a functional protein with a specific structure and function. The sequence of amino acids in a protein is determined by the sequence of nucleotides in the corresponding mRNA molecule.
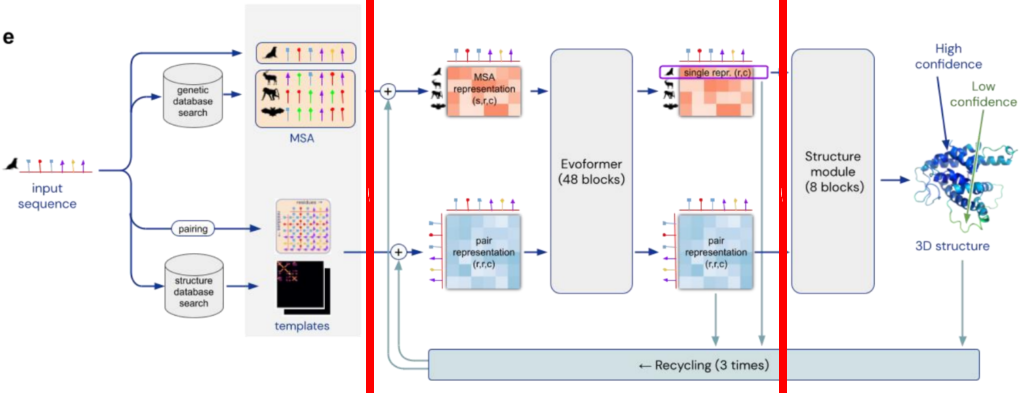
Structure of AlphaFold from Nature paper, and as described here.
https://www.nature.com/articles/s41592-023-01924-w A team of researchers led by Peter Kim at Stanford University has performed guided protein evolution using protein language models that were trained on millions of natural protein sequences.
https://aibusiness.com/nlp/meta-lays-off-team-behind-its-protein-folding-model
https://github.com/evolutionaryscale/esm
https://github.com/aws-samples/drug-discovery-workflows
https://github.com/lucidrains/alphafold3-pytorch

