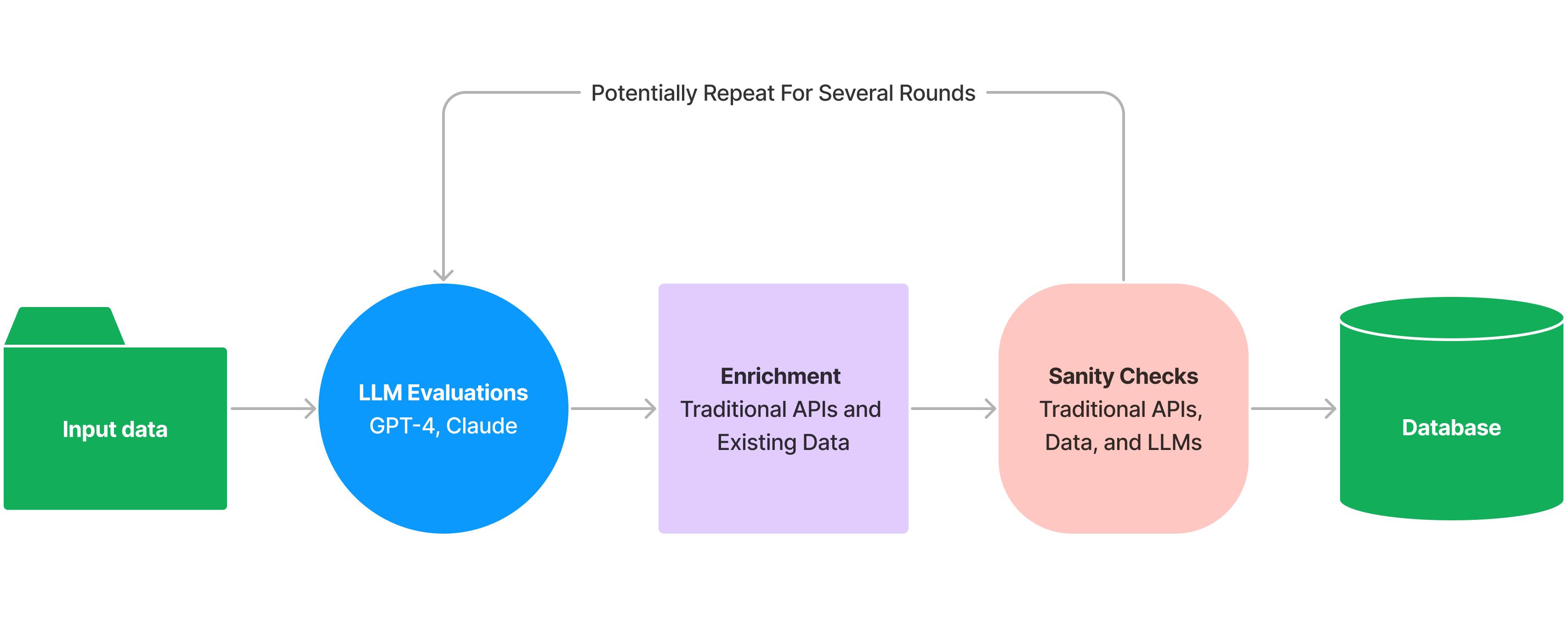
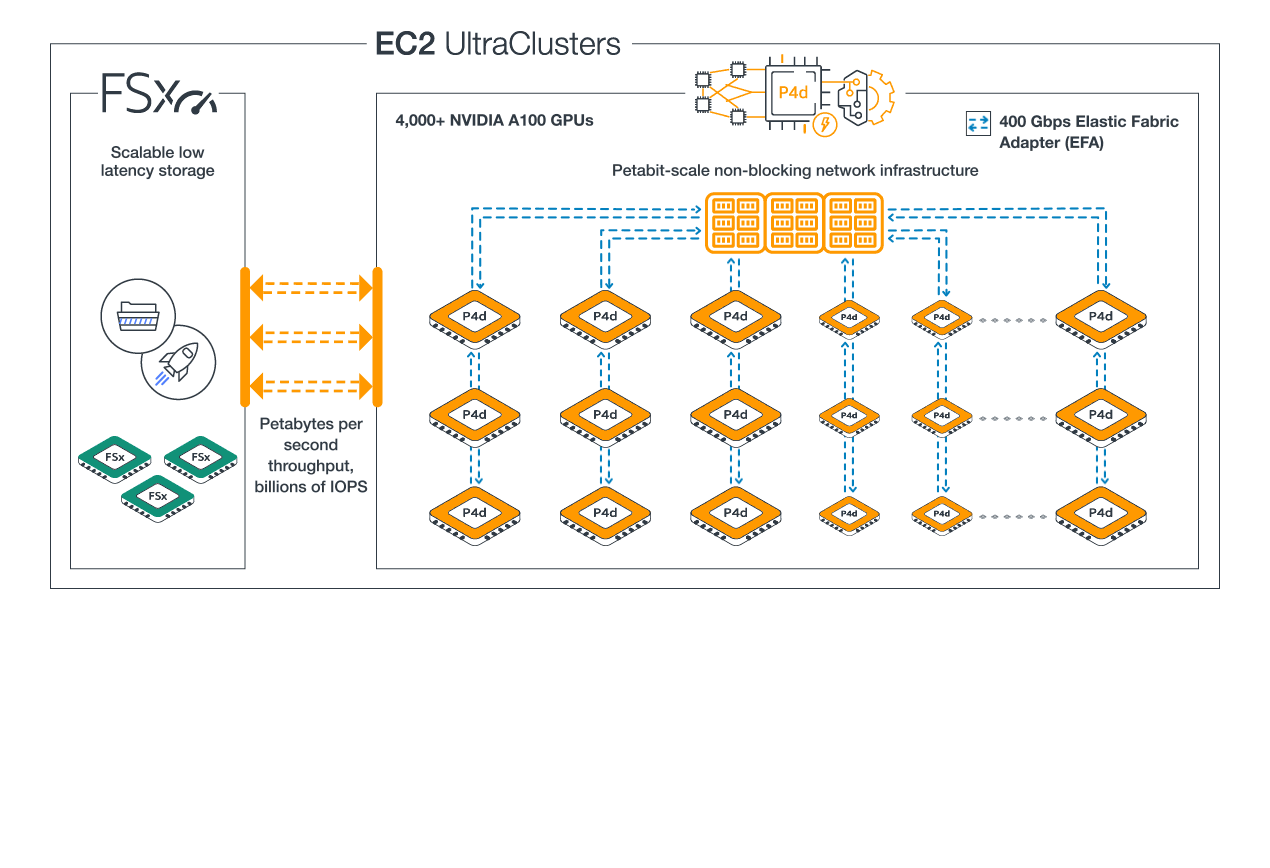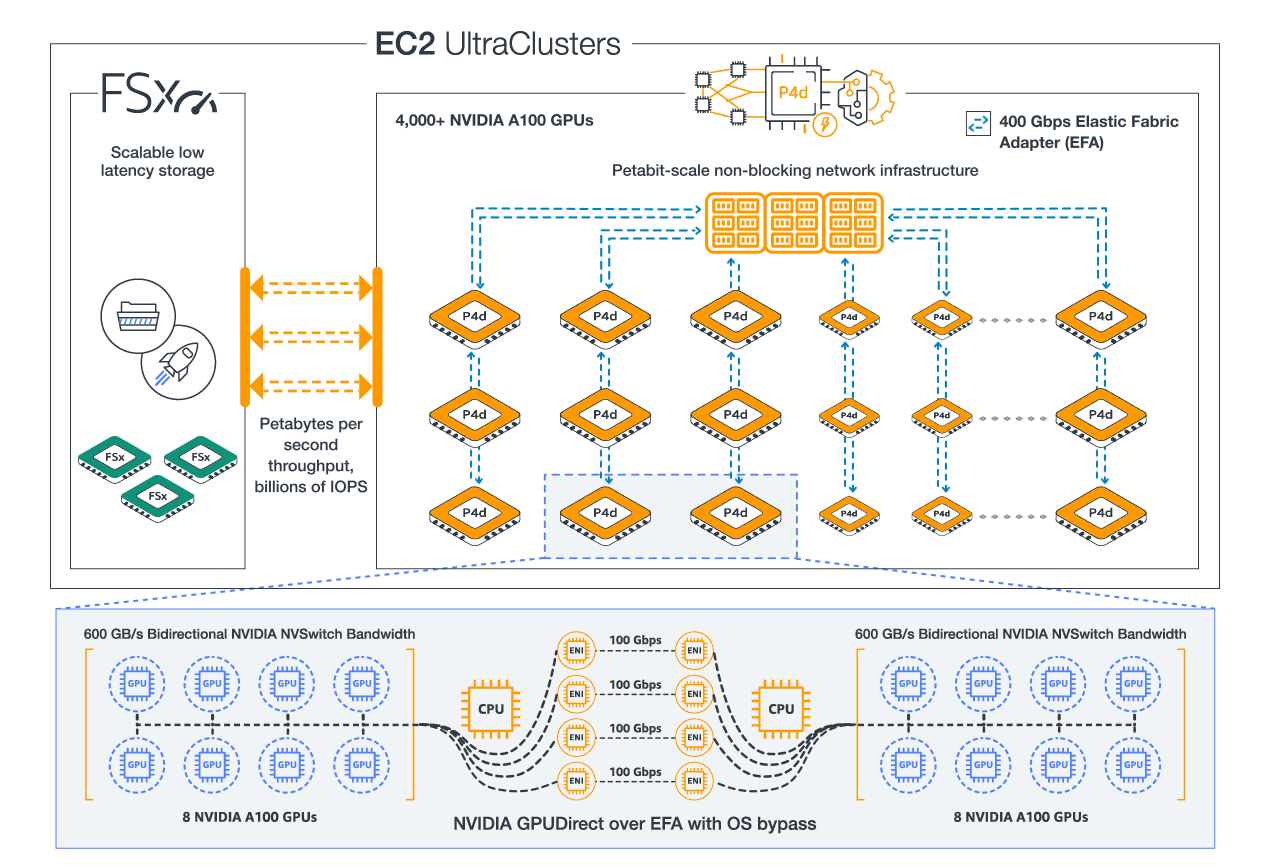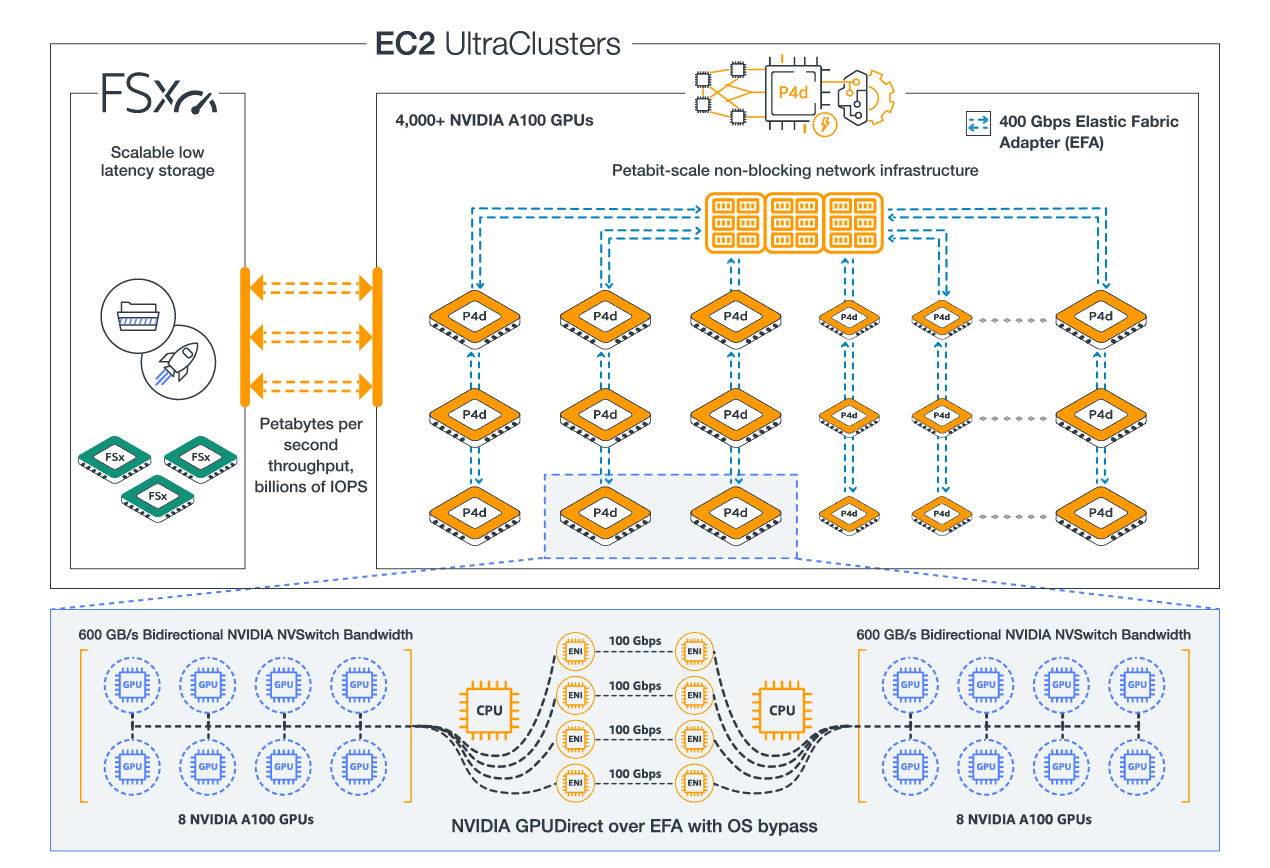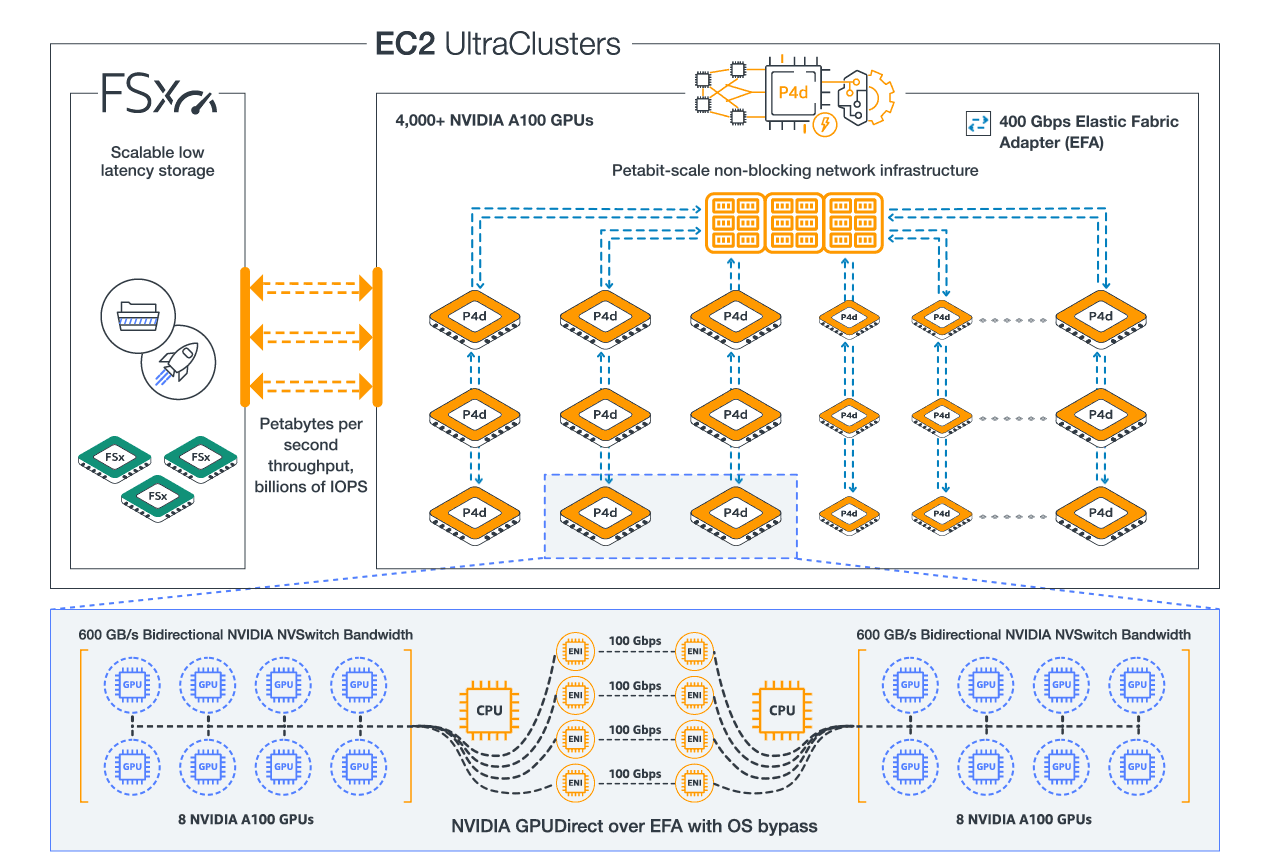
langchain enables agentic code to invoke one or more agents
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("how can one fine-tune a generative ai llm model ?")
here’s the output, showing it “thinking” through the steps to answer the question posed.
$ python langchain-test.py
> Entering new AgentExecutor chain...
I need to understand the process of fine-tuning a generative ai llm model
Action: Search
Action Input: "fine-tuning generative ai llm model"
Observation: A beginner-friendly introduction to fine-tuning Large language models using the LangChain framework on your domain data.
Thought: I need to understand the specific steps of fine-tuning a generative ai llm model
Action: Search
Action Input: "steps to fine-tune generative ai llm model"
Observation: This step involves training the pre-trained LLM on the task-specific dataset. The training process involves optimizing the model's weights and ...
Thought: I now know the final answer
Final Answer: The process of fine-tuning a generative ai llm model involves training the pre-trained LLM on the task-specific dataset and optimizing the model's weights and
parameters.
> Finished chain.
This required Python 3.10.10
Langchain interface to Vector Stores – https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
Langchain gallery – https://github.com/kyrolabs/awesome-langchain