YuniKorn is an alternative scheduler to the default scheduler in kubernetes which benefits complex and mixed workloads. It provides advanced scheduling options like workload queueing and shared quotas. This helps improve the user experience and provides cost savings by providing better resource utilization.
GangScheduling refers to a scheduling algorithm for parallel systems that schedules related threads or processes to run simultaneously on different processors. In the distributed computing world, this refers to the mechanism to schedule correlated tasks in an All or Nothing manner.
Bin packing refers to the process of allocation and reallocation of pods to nodes in a way that achieves a high utilization of the nodes. When a node has a low level of utilization, its pods are moved to a node with the highest level of utilization and that has space for the pods available; after which the low utilization node is freed and released.
Hugging Face supports around 100,000 pre-trained language models that can be used for various NLP tasks. The Hugging Face transformers library, which is a popular choice for NLP tasks such as text classification and machine translation, currently supports over 100 pre-trained language models. These models include popular models such as BERT, GPT-2, and RoBERTa. In addition Hugging Face provides tools and libraries that allow users to fine-tune and customize these models for specific tasks or datasets.
The datasets can be loaded using the python datasets package (pip install datasets). An overview is here.
CEO Clement Delangue, calls it the “GitHub of machine learning.” Its emphasis on an open, collaborative approach that made investors confident in the company’s $2 billion valuation, he said. “That’s what is really important to us, makes us successful and makes us different from others in the space.”
DistilBERT is a smaller, faster, and cheaper version of the BERT language model developed by Hugging Face by controlling the loss function during training of a ‘student model’ from a ‘teacher model’. It bucks the trend towards larger models, and instead focusses on training a more efficient model. It has been “distilled” to reduce its size and computational requirements, making it faster to train and more efficient to run. Despite being smaller than BERT, DistilBERT is able to achieve similar or even slightly better performance on many NLP tasks. The triple loss function is devised to include a distillation loss, a training loss and a cosine-distance loss.
Examples of generative models available on the Hugging Face platform include:
GPT-2: GPT-2 (Generative Pre-training Transformer 2) is a large-scale language model developed by OpenAI that can be used for tasks such as language translation and text generation.
BERT: BERT (Bidirectional Encoder Representations from Transformers) is a language model developed by Google that can be used for tasks such as language translation and text classification.
RoBERTa: RoBERTa (Robustly Optimized BERT Approach) is a language model developed by Facebook that is based on the BERT model and can be used for tasks such as language translation and text classification.
T5: T5 (Text-To-Text Transfer Transformer) is a language model developed by Google that can be used for tasks such as language translation and text summarization.
DistilBERT, described above. To generate text with DistilBERT, you would typically fine-tune the model on a specific task, such as machine translation or language generation, using a dataset that is relevant to the task. Once the model has been fine-tuned, you can use it to generate text by providing it with a prompt or seed text and letting it predict the next word or sequence of words.
Here’s an example of using transformers to generate some text.
import transformers
# Load the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('distilgpt2')
model = AutoModelWithLMHead.from_pretrained('distilgpt2')
# Encode the prompt
input_context_prompt = "Men on the moon "
input_ids = tokenizer.encode(input_context_prompt, return_tensors='pt') # encode input context
# Generate text
outputs = model.generate(input_ids=input_ids, max_length=40, temperature=0.9, num_return_sequences=10, do_sample=True)
# Sample candidate outputs and print
for i in range(10): # 10 output sequences were generated
print('Generated {}: {}'.format(i, tokenizer.decode(outputs[i], skip_special_tokens=True)))
Note the temperature parameter during model.generate(). A temperature of zero means the generation process will choose the most likely next word . A higher temperature allows for less likely words to be included in the generation process.
This line sets the sequence of operations for an ML pipeline in Airflow. source
A metaphor to think of Airflow is that of an air-traffic controller that is orchestrating, sequencing, mediating, managing the flow of the flights of airplanes (source). It is an example of the mediator pattern which decouples dependencies in a complex system. The airplanes do not talk directly to each other, they talk to the air-traffic controller.
A functional alternative to Airflow is to use a bunch of cron jobs to schedule bash scripts. Airflow instead defines pipelines as Directed Acyclic Graphs (DAGs) in python code. This critical talk on “Don’t use Apache Airflow” describes it as cron on steroids.
Each operation calls an operator to do the job locally or remotely.
How does it perform an operation remotely on another node ? ssh/remote execution ? docker daemon ? k8s operator ? There can be many different ways – this logic is encapsulated by an Executor.
Smart Contracts are relatively short blocks of code that run on the Ethereum Virtual Machine (EVM), and deal with tokens of value. For example a contract may release funds when certain preconditions such are met, such as time elapsed, or a signed request received. The number of smart contracts and the value of transactions in smart contracts has grown quite a bit in the last few years along with the prices of cryptocurrencies. The code of the Smart Contract is always publicly available as bytecode which can be reverse engineered, and often the source code in solidity language is often publicly available. As a result, bugs in smart contracts have become attractive exploit targets. EVMs are a distributed computing construct that run in parallel on a network of participating nodes, coordinating their actions by a consensus mechanism and protocol that runs between the nodes.
A collection of links on smart contract security –
https://solidity-by-example.org/variables/ Solidity has 3 types of variables 1. local (inside function), 2. state (inside contract, outside function), 3. global (e.g. block.timestamp, msg.sender – chain level. provides info about the blockchain)
Within the last year, bridges have accounted for a majority of the total funds stolen across all of the crypto ecosystem. Massive bridge hacks have occurred on average every few months, and each losing extremely large amounts of user funds. Some bridge hacks in the last couple of years have included the Axie Infinity Ronin bridge hack, losing users $625 million, the Wormhole bridge hack costing users $300 million, the Harmony bridge hack losing users $100 million, and just this last week the Nomad bridge hack, losing users almost $200 million.
Methods for Detecting attacks
Code reviews for reentrancy bugs
Detection of source of a txn as a bad actor
Using ML for code analysis and bad actor detection
https://github.com/DicksonWu654/ethdenverhack – This submission attempts using ML for detecting reentrancy attacks in Solidity code, by using transfer learning on DistilBERT, to train on good and bad smart contract code examples, and use the trained model to detect bad code on new code samples.
“from transformers import TFDistilBertModel, DistilBertTokenizerFast” # using Hugging Face Distilbert model
Seven security concerns in Machine Learning (ML) –
Data privacy and security: ML requires large amounts of data to be trained, and this data may contain sensitive or personal information. Appropriate measures need to be put in place to prevent data from being accessed by unauthorized parties.
Notebooks security: ML typically requires Jupyter or similar notebooks to be served for data scientists to work on data, code, and models, both individually and collaboratively. These notebooks need to be access controlled and protected from unauthorized access. This includes the code and git repos that host the code, and the model artifacts that the notebook uses or creates.
Model serving and inference security: ML models in production are commonly served and accessed over inference endpoints and such endpoints need authentication, authorization, encryption for protection against misuse. During model upgrades to an endpoint or changes to an endpoint and its configuration, a number of attacks are possible that are typical of a devops/devsecops pipeline. These need to be protected against.
Model security: Models can be vulnerable to attacks such as adversarial inputs, such as when an attacker intentionally manipulates the input to the model in order to cause it to make incorrect predictions. Another example is when the model makes an egregiously bad decision on an input, for example a self-driving car hitting an obstacle instead of avoiding it. It is important to harden the model and bound the decisions that come from its use.
Misuse: Even if a model works as designed, it can be misused, for example by generating fake or misleading content. It is important to consider the potential unintended consequences of using models and to put safeguards in place to prevent their misuse.
Bias: ML models can sometimes exhibit biases due to the data they are trained on. There should be a plan to identify biases in a model and take steps to mitigate them.
Intellectual property: ML models may be protected by intellectual property laws, and it is important to respect these laws and obtain the appropriate licenses when using language models developed by others.
An Agent is in an Environment. a) Agent reads Input (State) from Environment. b) Agent produces Output (Action) that affects its State relative to Environment c) Agent receives Reward (or feedback) for the Output produced. With the reward/feedback it receives it learns to produce better Output for given Input. The map that captures the set of available Actions, consequent Rewards and subsequent States for each State is called the Policy. This is a brief look at RL from the perspective of control theory. This map is actually a map of probabilities of the state transitions and another way of looking at RL is as a Markov Decision Process.
Where do neural networks come in ?
Optimal control theory considers control of a dynamical system such that an objective function is optimized (with applications including stability of rockets, helicopters). In optimal control theory, Pontryagin’s principle says: a necessary condition for solving the optimal control problem is that the control input should be chosen to minimize the control Hamiltonian. This “control Hamiltonian” is inspired by the classical Hamiltonian and the principle of least action. The goal is to find an optimal control policy function u∗(t) and, with it, an optimal trajectory of the state variable x∗(t) which by Pontryagin’s maximum principle are the arguments that maximize the Hamiltonian.
Derivatives are needed for the continuous optimizations. In which direction and by what amount should the weights be adjusted to reduce the observed error in the output ? What is the structure of the input to output map to begin with ? Deep learning models are capable of performing continuous linear and non-linear transformations, which in turn can compute derivatives and integrals. They can be trained automatically using real-world inputs, outputs and feedback. So a neural network can provide a system for sophisticated feedback-based non-linear optimization of the map from Input space to Output space. The structure of the network is being learned empirically. For example this 2017 paper uses 8 layers (5 convolutional and 3 fully connected) to train a neural network on the ImageNet database.
The above could be accomplished by a feedforward neural network that is trained with a feedback (reward). Additionally a recurrent neural network could encode a memory into the system by making reference to previous states (likely with higher training and convergence costs).
Model-free reinforcement learning does not explicitly learn a model of the environment.
The optimal action-value function obeys an identity known as the Bellman equation. If the quality of the action selection were known for every state then the optimal strategy at every state is to select the action that maximizes the (local) quality. [ Playing Atari with Deep Reinforcement Learning, https://arxiv.org/pdf/1312.5602.pdf ]
Manifestations of RL: Udacity self-driving course – lane detection. Karpathy’s RL blog post has an explanation of a network structure that can produce policies in a malleable manner, called policy gradients.
Practical issues in Reinforcement Learning –
Raw inputs vs model inputs: There is the problem of mapping inputs from real-world to the actual inputs to a computer algorithm. Volume/quality of information – high vs low requirement.
Exploitation vs exploration dilemma: https://en.wikipedia.org/wiki/Multi-armed_bandit. Simple exploration methods are the most practical. With probability ε, exploration is chosen, and the action is chosen uniformly at random. With probability 1 − ε, exploitation is chosen, and the agent chooses the action that it believes has the best long-term effect (ties between actions are broken uniformly at random). ε is usually a fixed parameter but can be adjusted either according to a schedule (making the agent explore progressively less), or adaptively based on heuristics.
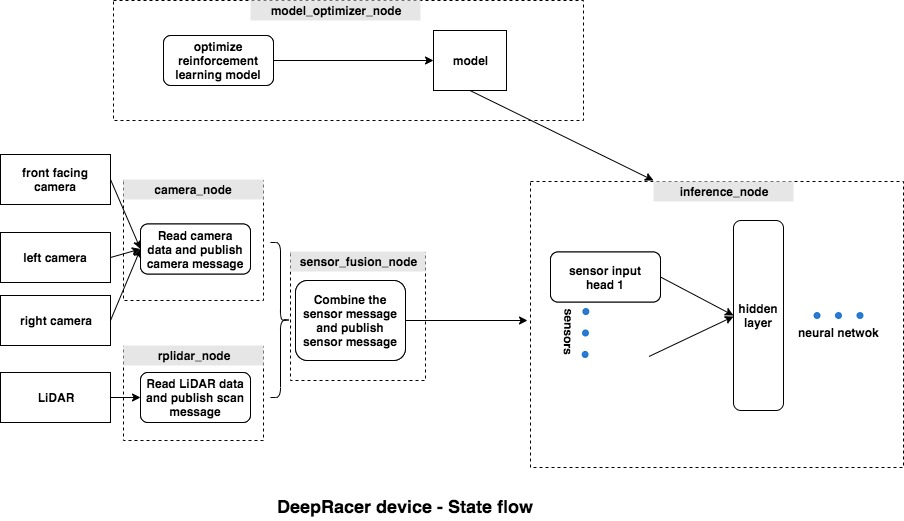
AWS DeepRacer. Allows exploration of RL. Simplifies the mapping of camera input to computer input, so one can focus more on the reward function and deep learning aspects. The car has a set of possible actions (change heading, change speed). The RL task is to predict the actions based on the inputs.
What are some of the strategies applied to winning DeepRacer ?
“DeepRacer: Educational Autonomous Racing Platform for Experimentation with Sim2Real Reinforcement Learning” – https://arxiv.org/pdf/1911.01562.pdf
DeepRacer uses RLLib which brings forth a key idea of encapsulating parallelism in the context of AI applications, as described in RLlib: Abstractions for Distributed Reinforcement Learning. RLLib is part of Ray, described in Ray: A Distributed Framework for Emerging AI Applications . Encapsulating parallelism means that individual components specify their own internal parallelism and resources requirements and can be used by other components without any knowledge of these. This allows a larger system to be built from modular components.
OpenAI Gym offers a suite of environments for developing and comparing RL algorithms. It emphasizes environments over agents, complexity over performance, knowledge sharing over competition. https://github.com/openai/gym , Open AI Gym paper. Here’s a code snippet from this paper of how they see an agent interact with the environments over 100 steps of a training episode.
ob0 = env.reset() # sample environment state, return first observation
a0 = agent.act(ob0) # agent chooses first action
ob1, rew0, done0, info0 = env.step(a0) # environment returns observation,
# reward, and boolean flag indicating if the episode is complete.
a1 = agent.act(ob1)
ob2, rew1, done1, info1 = env.step(a1)
...
a99 = agent.act(o99)
ob100, rew99, done99, info2 = env.step(a99)
# done99 == True => terminal
RL is not a fit for every problem. Alternative approaches with better explainability and determinism include behavior trees, vectorization/VectorNet, …
Deep learning is being applied to combinatorial optimization problems. A very intriguing talk by Anna Goldie discussed an application of RL to chip design that cuts down the time for layout optimization and which in turn enables optimizing of the chip design for a target software stack in simulation before the chip goes to production. Here’s a paper – graph placement methodology for fast chip design.
A snippet on how the research direction evolved to a learning problem.
“Chip floorplanning as a learning problem
The underlying problem is a high-dimensional contextual bandits problem but, as in prior work, we have chosen to reformulate it as a sequential Markov decision process (MDP), because this allows us to more easily incorporate the problem constraints as described below. Our MDP consists of four key elements: (1) States encode information about the partial placement, including the netlist (adjacency matrix), node features (width, height, type), edge features (number of connections), current node (macro) to be placed, and metadata of the netlist graph (routing allocations, total number of wires, macros and standard cell clusters). (2) Actions are all possible locations (grid cells of the chip canvas) onto which the current macro can be placed without violating any hard constraints on density or blockages. (3) State transitions define the probability distribution over next states, given a state and an action. (4) Rewards are 0 for all actions except the last action, where the reward is a negative weighted sum of proxy wirelength, congestion and density, as described below.
We train a policy (an RL agent) modelled by a neural network that, through repeated episodes (sequences of states, actions and rewards), learns to take actions that will maximize cumulative reward (see Fig. 1). We use proximal policy optimization (PPO) to update the parameters of the policy network, given the cumulative reward for each placement.”
Their diagram:
“An embedding layer encodes information about the netlist adjacency, node features and the current macro to be placed. The policy and value networks then output a probability distribution over available grid cells and an estimate of the expected reward for the current placement, respectively. id: identification number; fc: fullyconnected layer; de-conv: deconvolution layer”
“Fig. 1 | Overview of our method and training regimen.In each training iteration, the RL agent places macros one at a time (actions, states and rewards are denoted byai, si and ri, respectively). Once all macros are placed, the standard cells are placed using a force-directed method. The intermediate rewards are zero. The reward at the end of each iteration is calculated as a linear combination of the approximate wirelength, congestion and density, and is provided as feedback to the agent to optimize its parameters for the next iteration.”
PyTorch is an open source machine learning framework that is primarily used for building deep learning models. The framework is built on top of the Torch library and is implemented in Python, with support for C++ and CUDA.
The main C++ classes in PyTorch are:
Tensor: This is the core object in PyTorch and represents a multi-dimensional array. Tensors are the basic building blocks of a PyTorch model and are used to store and manipulate data.
Autograd: This is PyTorch’s automatic differentiation engine, which allows developers to compute gradients of tensors with respect to a loss function. The autograd module also provides a set of functions for computing gradients of complex functions.
nn.Module: This is a base class for all neural network modules in PyTorch. It provides a convenient way to define and organize layers of a neural network, as well as a set of useful methods for training and evaluating the model.
Optimizer: This is a class that implements various optimization algorithms, such as stochastic gradient descent (SGD), Adam, and Adagrad. The optimizer is used to update the parameters of a model during training.
DataLoader: This is a utility class that provides an efficient way to load and preprocess large datasets for training a model. The DataLoader class can be used to batch and shuffle data, as well as to apply various transformations to the data.
PyTorch’s autograd engine implements a variant of reverse-mode automatic differentiation, which is also known as backpropagation. This algorithm efficiently calculates the gradients of the output with respect to each input variable by traversing the computational graph in reverse order, propagating the gradients backwards through each operation using the chain rule.
In this paper – “DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks”, the authors discuss a method for learning a global model from several individual time series.
Let’s break down some aspects of the approach and design.
“In probabilistic forecasting one is interested in the full predictive distribution, not just a single best realization, to be used in downstream decision making systems.”
The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term (an imperfectly predictable term).
Recurrent Neural Network is used to refer to NNs with an infinite impulse response, and are used for speech recognition, handwriting recognition and such tasks involving sequences. https://en.wikipedia.org/wiki/Recurrent_neural_network
An LSTM or The Long Short-Term Memory (LSTM) is a type of RNN, that came about to solve a problem of vanishing gradients in previous RNN designs. An LSTM cell can process data sequentially and keep its hidden state through time.
A covariate is an independant random variable, with which the target random variable is assumed to have some covariance.
The approach has distinct features described in this snippet
“In addition to providing better forecast accuracy than previous methods, our approach has a number key advantages compared to classical approaches and other global methods: (i) As the model learns seasonal behavior and dependencies on given covariates across time series, minimal manual feature engineering is needed to capture complex, group-dependent behavior; (ii) DeepAR makes probabilistic forecasts in the form of Monte Carlo samples that can be used to compute consistent quantile estimates for all sub-ranges in the prediction horizon; (iii) By learning from similar items, our method is able to provide forecasts for items with little or no history at all, a case where traditional single-item forecasting methods fail; (vi) Our approach does not assume Gaussian noise, but can incorporate a wide range of likelihood functions, allowing the user to choose one that is appropriate for the statistical properties of the data. Points (i) and (iii) are what set DeepAR apart from classical forecasting approaches, while (ii) and (iv) pertain to producing accurate, calibrated forecast distributions learned from the historical behavior of all of the time series jointly, which is not addressed by other global methods (see Sec. 2). Such probabilistic forecasts are of crucial importance in many applications, as they—in contrast to point forecasts—enable optimal decision making under uncertainty by minimizing risk functions, i.e. expectations of some loss function under the forecast distribution.”
“A large machine learning job spans many nodes and runs most efficiently when it has access to all of the hardware resources on each node. This allows GPUs to cross-communicate directly using NVLink, or GPUs to directly communicate with the NIC using GPUDirect. So for many of our workloads, a single pod occupies the entire node. Any NUMA, CPU, or PCIE resource contention aren’t factors for scheduling. Bin-packing or fragmentation is not a common problem. Our current clusters have full bisection bandwidth, so we also don’t make any rack or network topology considerations. All of this means that, while we have many nodes, there’s relatively low strain on the scheduler.”
“We use iptables tagging on the host to track network resource usage per Namespace and pod. This lets researchers visualize their network usage patterns. In particular, since a lot of our experiments have distinct Internet and intra-pod communication patterns, it’s often useful to be able to investigate where any bottlenecks might be occurring.”
“the default setting for Fluentd’s and Datadog’s monitoring processes was to query the apiservers from every node in the cluster (for example, this issue which is now fixed). We simply changed these processes to be less aggressive with their polling, and load on the apiservers became stable again”
“ARP cache size increase..is particularly relevant in Kubernetes clusters since every pod has its own IP address which consumes space in the ARP cache”
“We use Kubernetes mainly as a batch scheduling system and rely on our autoscaler to dynamically scale up and down our cluster — this lets us significantly reduce costs for idle nodes, while still providing low latency while iterating rapidly. The default kube-scheduler policy is to spread out load evenly among nodes, but we want the opposite so that unused nodes can be terminated and also so that large pods can be scheduled quickly.”
A position paper from CNCF on securing the software supply chain, talks about hardening the software construction process by hardening each of the links in the software production chain –
Quote – “To operationalize these principles in a secure software factory several stages are needed. The software factory must ensure that internal, first party source code repositories and the entities associated with them are protected and secured through commit signing, vulnerability scanning, contribution rules, and policy enforcement. Then it must critically examine all ingested second and third party materials, verify their contents, scan them for security issues, evaluate material trustworthiness, and material immutability. The validated materials should then be stored in a secure, internal repository from which all dependencies in the build process will be drawn. To further harden these materials for high assurance systems it is suggested they should be built directly from source.
Additionally, the build pipeline itself must be secured, requiring the “separation of concerns” between individual build steps and workers, each of which are concerned with a separate stage in the build process. Build Workers should consider hardened inputs, validation, and reproducibility at each build. Finally, the artifacts produced by the supply chain must be accompanied by signed metadata which attests to their contents and can be verified independently, as well as revalidated at consumption and deployment.”
The issue is that software development is a highly collaborative process. Walking down the chain and ensuring the ingested software packages are bug-free is where it gets challenging.
The Department of Defense Enterprise DevSecOps Reference design, speaks to the aspect of securing the build pipeline –
Distributed Training aims to reduce the time to train an model in machine learning, by splitting the training workload across multiple nodes. It has gained in importance as data sizes, model sizes and complexity of training have grown. Training consists of iteratively minimizing an objective function by running the data through a model and determining a) the error and the gradients with which to adjust the model parameters (forward path) and b) the updated model parameters using calculated gradients (reverse path). The reverse path always requires synchronization between the nodes, and in some cases the forward path also requires such communication.
There are three approaches to distributed training – data parallelism, model parallelism and data-model parallelism. Data parallelism is the more common approach and is preferred if the model fits in GPU memory (which is increasingly hard for large models).
In data parallelism, we partition the data on to different GPUs and and run the same model on these data partitions. The same model is present in all GPU nodes and no communication between nodes is needed on the forward path. The calculated parameters are sent to a parameter server, which averages them, and updated parameters are retrieved back by all the nodes to update their models to the same incrementally updated model.
In model parallelism, we partition the model itself into parts and run these on different GPUs. This applies to large models such as large language models (LLMs) that do not fit in a single GPU.
A paper on Parameter Servers is here, on Scaling Distributed Machine Learning with the Parameter Server.
To communicate the intermediate results between nodes the MPI primitives are leveraged, including AllReduce.
The amount of training data for BERT is ~600GB. BERT-Tiny model is 17MB, BERT-Base model is ~400MB. During training a 16GB memory GPU sees an OOM error.
Horovod core principles are based on the MPI concepts size, rank, local rank, allreduce, allgather, and broadcast. These are best explained by example. Say we launched a training script on 4 servers, each having 4 GPUs. If we launched one copy of the script per GPU:
Size would be the number of processes, in this case, 16.
Rank would be the unique process ID from 0 to 15 (size – 1).
Local rank would be the unique process ID within the server from 0 to 3.
Allreduce is an operation that aggregates data among multiple processes and distributes results back to them. Allreduce is used to average dense tensors. Here’s an illustration from the MPI Tutorial:
Allgather is an operation that gathers data from all processes in a group then sends data back to every process. Allgather is used to collect values of sparse tensors. Here’s an illustration from the MPI Tutorial:
Broadcast is an operation that broadcasts data from one process, identified by root rank, onto every other process. Here’s an illustration from the MPI Tutorial:
Horovod switched from using MPI to using NCCL (NVidia Collective Communications Library) for distributing initial weights and biases, and intermediate weights and biases after each training step .
NCCL is a library that provides primitives for communication between multiple GPUs both within a node and across different nodes.
Horovod continues to use MPI for other functions that do not involve inter-GPU communication, such as informing processes on different nodes of their id (aka rank), master vs non-master status for coordination between processes and for sharing the total number of nodes.
NVidia NCCL uses NVLink which is the hardware interconnect that connects multiple GPUs.
NVLink is a high-speed, point-to-point interconnect technology developed by NVIDIA that is designed to enable high-bandwidth communication between processors, GPUs, and other components in a system.
NVLink 1.0, which was introduced in 2016, provides a maximum bidirectional bandwidth of 80 GB/s per link. This means that data can be transferred between two devices at a rate of up to 80 GB/s in each direction.
NVLink 2.0, which was introduced in 2017, provides a maximum bidirectional bandwidth of 300 GB/s per link. This represents a significant increase in bandwidth compared to NVLink 1.0, and allows for even faster data transfer rates between devices.
NVLink 3.0, which was introduced in 2021, provides a maximum bidirectional bandwidth of 600 GB/s per link, making it the fastest version of NVLink to date.
ML Training on images and text together leads to certain neurons holding information of both images and text – multimodal neurons.
When the type of the detected object can be changed by tricking the model into recognizing a textual description instead of a visual description- that can be called a typographic attack.
Intriguing concepts indicating that a fluid crossover from text to images and back is almost here.
There are a few potential security concerns to consider when working with language models:
Data privacy: Language models often require large amounts of data to be trained, and this data may contain sensitive or personal information. It is important to ensure that this data is protected and that appropriate measures are in place to prevent it from being accessed by unauthorized parties.
Model security: Language models can be vulnerable to attacks such as adversarial examples, in which an attacker intentionally manipulates the input to the model in order to cause it to make incorrect predictions. It is important to consider the security of the model and take steps to protect it against these types of attacks.
Misuse: Language models have the potential to be misused, for example by generating fake or misleading content. It is important to consider the potential unintended consequences of using language models and to put safeguards in place to prevent their misuse.
Bias: Language models can sometimes exhibit biases due to the data they are trained on. It is important to consider the potential biases in a model and take steps to mitigate them.
Intellectual property: Language models may be protected by intellectual property laws, and it is important to respect these laws and obtain the appropriate licenses when using language models developed by others.
The routing infrastructure that routes a client request to the nearest DNS server is typically the Border Gateway Protocol (BGP) routing protocol. BGP is the protocol that is used to exchange routing information between different Internet Service Providers (ISPs) and networks. It is a dynamic and scalable protocol that can adapt to changes in the network topology, link cost, and congestion levels.
The BGP routing table is used by a router to determine the best path for forwarding the packet based on several factors, such as network topology, link cost, and congestion levels. The routing table is continuously updated based on changes in the network conditions, which ensures that the client request is directed to the nearest and most responsive DNS server.
BGP is vulnerable to several types of attacks, including the advertisement of incorrect or malicious routes by a malicious actor. This type of attack is known as a BGP hijack, and it can result in traffic being redirected to an unintended destination or being dropped altogether. A list of BGP hijack attacks – here.
There are several mechanisms that can help prevent or mitigate BGP hijacks and other types of BGP attacks:
Route origin validation (ROV): ROV is a technique that allows routers to verify the authenticity of a BGP route advertisement by checking the Autonomous System (AS) number of the originator against a trusted database. If the AS number matches the expected value, the route is considered valid; otherwise, it is rejected.
Resource Public Key Infrastructure (RPKI): RPKI is a system that uses digital certificates to authenticate the ownership and authorization of IP address blocks and AS numbers. Routers can use RPKI to verify the authenticity of BGP route advertisements and reject invalid or unauthorized routes.
BGPSEC: BGPSEC is an extension to BGP that provides a cryptographic mechanism for verifying the authenticity and integrity of BGP route advertisements. BGPSEC uses digital signatures to ensure that the route advertisement has not been tampered with or modified by a malicious actor.
Route filtering: Network operators can use route filtering to limit the propagation of BGP route advertisements based on certain criteria, such as the origin AS number or the geographic location of the route.
A cloudflare blog on implementing RPKI is here. An AWS blog on implementing RPKI is here.
These require the cooperation and coordination of network operators and ISPs. BGP security is an ongoing challenge, and new threats and vulnerabilities may emerge over time, which requires constant vigilance and updates to the security mechanisms.
The underlying concepts of Autonomous Systems, Gateways, neighbor acquisition, reachability and network route determination are well described in https://www.rfc-editor.org/rfc/rfc827 (1982), which is the RFC for EGP, a precursor of BGP.
BGP was designed to be more scalable than EGP. It achieved greater scalability by 1) supporting CIDR instead of classful IP addressing, 2) by summarizing or aggregating multiple IP network prefixes into a single prefix, 3) by supporting multiple paths to a destination and 4) by supporting path attributes that let the recipient determine the best path.