Smithy is an Apache-2.0 licensed, protocol-agnostic IDL for defining APIs, generating clients, servers and documentation. https://github.com/awslabs/smithy
We want to walk through some common metrics in classification problems – such as accuracy, precision and recall – to get a feel for when to use which metric. Say we are looking for a needle in a haystack. There are very few needles in a large haystack full of straws. An automated machine is sifting through the objects in the haystack and predicting for each object whether it is a straw or a needle. A reasonable predictor will predict a small number of objects as needles and a large number as straws. A prediction has two attributes – positive/negative and accurate/inaccurate.
Positive Prediction: the object at hand is predicted to be the needle. A small number.
Negative Prediction: the object at hand is predicted not to be a needle. A large number.
True_Positive: of the total number of predictions, the number of predictions that were positive and correct. Correctly predicted Positives (needles). A small number.
True_Negative: of the total number of predictions, the number of predictions that were negative and correct. Correctly predicted Negatives (straws). A large number.
False_Positive: of the total number of predictions, the number of predictions that are positive but the prediction is incorrect. Incorrectly predicted Positives (straw predicted as needle). Could be large as the number of straws is large, but assuming the total number of predicted needles is small, this is less than or equal to predicted needles, hence small.
False_Negative: of the total number of predictions, the number of predictions that are negative but the prediction is incorrect. Incorrectly predicted Negatives (needle predicted as straw). Is this a large number ? It is unknown – this class is not large just because the class of negatives is large – it depends on the predictor and a “reasonable” predictor which predicts most objects as straws, could also predict many needles as straws. This is less than or equal to the total number of needles, hence small.
Predicted_Positives = True_Positives + False_Positives = Total number of objects predicted as needles.
Actual Positives = Actual number of needles, which is independant of the number of predictions either way, however Actual Positives = True Positives + False Negatives.
Accuracy = nCorrect _Predictons/nTotal_Predictions=(nTrue_Positives+nTrue_Negatives) / (nPredicted_Positives +nPredicted_Negatives) . # the reasonable assumption above is equivalent to a high accuracy. Most predictions will be hay, and be correct in this simply because of the skewed distribution. This does not shed light on FP or FN.
Precision = nTrue_Positives / nPredicted_Positives # correctly_identified_needles/predicted_needles; this sheds light on FP; Precision = 1 => FP=0 => all predictions of needles are in fact needles; a precision less than 1 means we got a bunch of hay with the needles – gives hope that with further sifting the hay can be removed. Precision is also called Specificity and quantifies the absence of False Positives or incorrect diagnoses.
Recall = nTrue_Positives / nActual_Positives = TP/(TP+FN)# correctly_identified_needles/all_needles; this sheds light on FN; Recall = 1 => FN = 0; a recall less than 1 is awful as some needles are left out in the sifting process. Recall is also called Sensitivity .
Precision > Recall => FN is higher than FP
Precision < Recall => FN is lower than FP
If at least one needle is correctly identified as a needle, both precision and recall will be positive; if zero needles are correctly identified, both precision and recall are zero.
F1 Score is the harmonic mean of Precision and Recall. 1/F1 = 1/2(1/P + 1/R) . F1=2PR/(P+R) . F1=0 if P=0 or R=0. F1=1 if P=1 and R=1.
ROC/AUC rely on Recall (=TP/TP+FN) and another metric False Positive Rate defined as FP/(FP+TN) = hay_falsely_identified_as_needles/total_hay . As TN >> FP, this should be close to zero and does not appear to be a useful metric in the context of needles in a haystack; as are ROC/AuC . The denominators are different in Recall and FPR, total needles and total hay respectively.
There’s a bit of semantic confusion when saying True Positive or False Positive. These shorthands can be interpreted as- it was known that an instance was a Positive and a label of True or False was applied to that instance. But what we mean is that it was not known whether the instance was a Positive, and that a determination was made that it was a Positive and this determination was later found to be correct (True) or incorrect (False). Mentally replace True/False with ‘Correct/Incorrectly identified as’ to remove this confusion.
Normalization: scale of 0-1, or unit norm; useful for dot products when calculating similarity.
Standardization: zero mean, divided by standard deviation; useful in neural network/classifier inputs
Regularization: used to reduce sensitivity to certain features. Uses regression. L1: Lasso regression L2: Ridge regression
Confusion matrix: holds number of predicted values vs known truth. Square matrix with size n equal to number of categories.
I wanted to get a better understanding of firecracker microVM security, from the bottom up. A few questions –
a) how does firecracker design achieve a smaller threat surface than a typical vm/container ?
b) what mechanisms are available to secure code running in a microvm ?
c) and lastly, how can microvms change security considerations when deploying code for web services ?
The following design elements contribute to a smaller threat surface:
minimal design, in a memory safe, compact, readable rust language
minimal guest virtual device model: a network device, a block I/O device, a timer, a KVM clock, a serial console, and a partial keyboard
minimal networking; from docs/vsock.md : “The Firecracker vsock device aims to provide full virtio-vsock support to software running inside the guest VM, while bypassing vhost kernel code on the host. To that end, Firecracker implements the virtio-vsock device model, and mediates communication between AF_UNIX sockets (on the host end) and AF_VSOCK sockets (on the guest end).”
static linking of the firecracker process limits dependancies
seccomp BPF limits the system calls to 35 allowed calls, 30 with simple filtering, 5 with advanced filtering that limits the call based on parameters (SeccompFilter::new call in vmm/src/default_syscalls/filters.rs, seccomp/src/lib.rs)
The production security setup recommends using jailer to apply isolation based on cgroups, namespaces, seccomp. These techniques are typical of container isolation and act in addition to KVM based isolation.
The Firecracker Host Security Configuration recommends a series of checks to mitigate side-channel issues for a multi-tenant system:
Disable Simultaneous Multithreading (SMT)
Check Kernel Page-Table Isolation (KPTI) support
Disable Kernel Same-page Merging (KSM)
Check for speculative branch prediction issue mitigation
Apply L1 Terminal Fault (L1TF) mitigation
Apply Speculative Store Bypass (SSBD) mitigation
Use memory with Rowhammer mitigation support
Disable swapping to disk or enable secure swap
How is the firecracker process organized ? The docs/design.md has the following descriptions:
Internal Design: Each Firecracker process encapsulates one and only one microVM. The process runs the following threads: API, VMM and vCPU(s). The API thread is responsible for Firecracker’s API server and associated control plane. It’s never in the fast path of the virtual machine. The VMM thread exposes the machine model, minimal legacy device model, microVM metadata service (MMDS) and VirtIO device emulated Net and Block devices, complete with I/O rate limiting. In addition to them, there are one or more vCPU threads (one per guest CPU core). They are created via KVM and run the `KVM_RUN` main loop. They execute synchronous I/OÂ and memory-mapped I/O operations on devices models.
Threat Containment: From a security perspective, all vCPU threads are considered to be running malicious code as soon as they have been started; these malicious threads need to be contained. Containment is achieved by nesting several trust zones which increment from least trusted or least safe (guest vCPU threads) to most trusted or safest (host). These trusted zones are separated by barriers that enforce aspects of Firecracker security. For example, all outbound network traffic data is copied by the Firecracker I/O thread from the emulated network interface to the backing host TAP device, and I/O rate limiting is applied at this point.
What about mechanisms to secure the code running inside firecracker ? The serverless environment, AWS Lambda, and its security best practices are a place to start. Resources on these are here, here, here and here. AWS API gateway supports input validation, as described here. While serverless reduces the attack surface, the web threats such as OWASP still apply and must be taken into account during design and testing.
For the last question – uVMs and serverless appear to offer a promising model to build a service incrementally from small secure building blocks – and this is something to explore further.
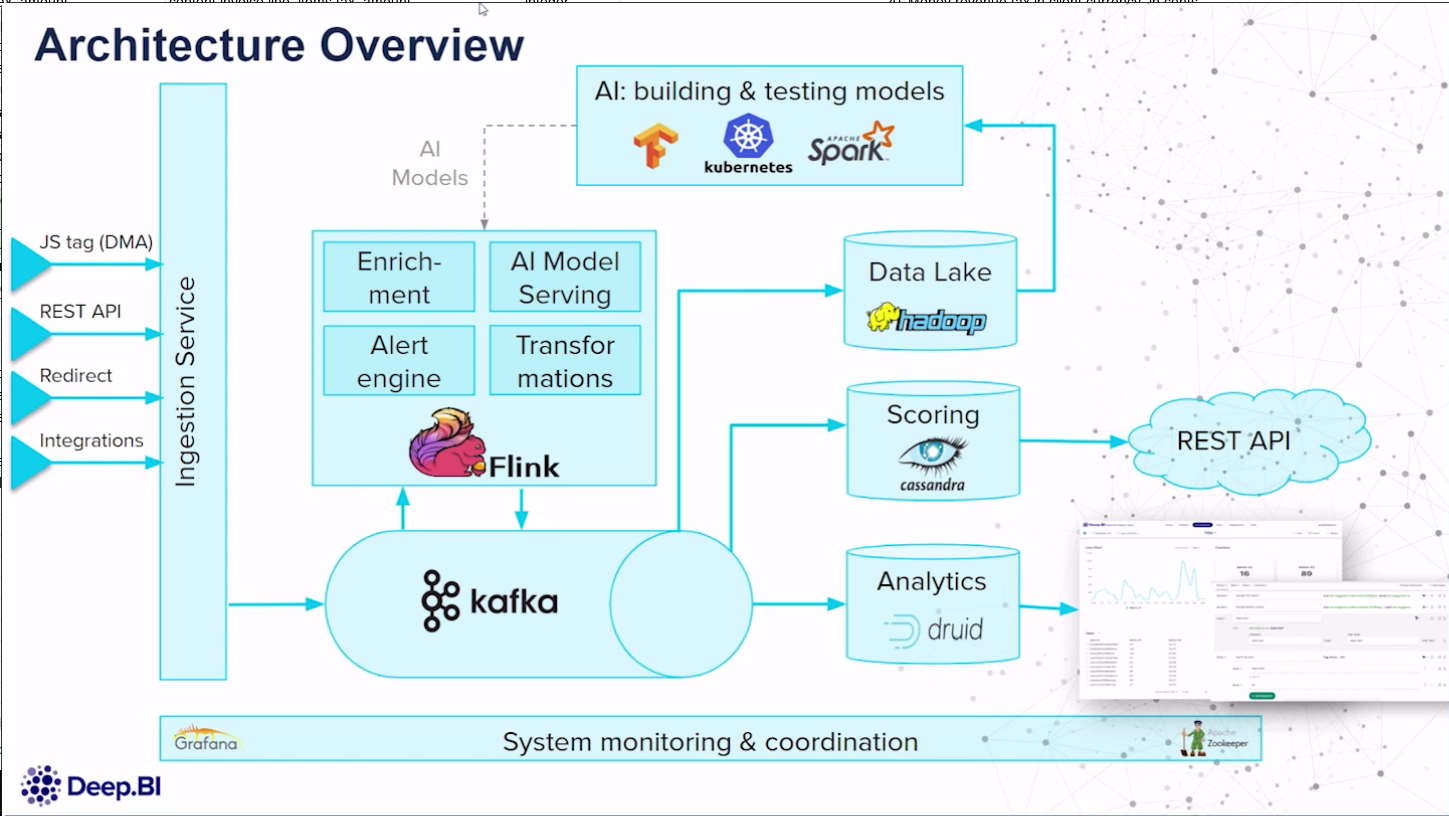
Druid is different from Flink and Spark streaming in that it is not a streaming system. Flink can apply real-time data transformations on the data, which can then be ingested into Druid via Kafka, to power real-time dashboards.
These are some notes from a talk by Aviatrix last week. Many customers get started with Aviatrix orchestration system for deploying AWS Transit Gateway (TGW) and Direct Connect. The transit gateway is the hub gateway that connects multiple VPCs with an on-premise link, possibly over Direct Connect. The Aviatrix product can then deploy and manage multiple VPCs and the communication between them, directing which VPC can talk to which other VPC. It controls the communication by simply deleting the routes.
The advanced transit controller solution is useful for multiple regions, to manage the communication between regions. Another aspect is there are high speed interconnects between the cloud providers and Aviatrix builds an overlay that bridges between public clouds. Multi-account communication and secure communication between the networks using segmentation can be enabled.
According to Aviatrix, AWS’s motto is go build, and do it yourself, it is designed for the builders. But when you go beyond 3 VPCs to 3000 VPCs, one needs a solution to manage the routes in an automated manner. This is the situation for many larger customers. For smaller ones where there are Production, Development and Edge/On-premise network components to manage it also finds use.
Remote user VPN is another use case. Not only can one VPN in and get to all the VPCs, but specify which CIDR they can get to and other restrictions.
“The attention mechanism allows the model to create the context vector as a weighted sum of the hidden states of the encoder RNN at each previous timestamp.”
“Transformer is a type of model based entirely on attention, and does not require recurrent or convolutional layers”
Context vector is the output of the Encoder in an Encoder-Decoder network (EDN). EDNs struggle to retain all the required information for the decoder to accurately decode. Attention is a mechanism to solve this problem.
“Attention mechanisms let a model directly look at, and draw from, the state at any earlier point in the sentence. The attention layer can access all previous states and weighs them according to some learned measure of relevancy to the current token, providing sharper information about far-away relevant tokens.”
GPT: Generative Pre-Trained Transformer. Unlike BERT, it is generative and not geared to comprehension, translation or summarization tasks, but instead writing or generative tasks. It uses unsupervised learning to train a deep neural network with a seq2seq model. It does not use reinforcement learning (feedback from environment) or supervised learning. It uses “masked self-attention” to predict the next text during training on its dataset.
The term “generative” is used to emphasize GPT’s ability to generate new, original text, rather than just processing or analyzing text that already exists. A generative model is a type of machine learning model that is trained to produce data, such as text, images, or music, that is similar to the data it was trained on. GPT is a generative model because it is trained on a large corpus of text data and can then generate new text that is similar to the text in its training data. This allows GPT to produce human-like text on a wide range of topics, which can be useful for a variety of applications, such as language translation, text summarization, and question answering.
A “transformer” is a type of neural network architecture that was introduced in 2017. It is a deep learning model that is used for natural language processing tasks, such as language translation and text summarization. A transformer consists of two main components: an encoder, which processes the input text, and a decoder, which generates the output text. The encoder and decoder are connected by a series of attention mechanisms, which allow the model to focus on different parts of the input text as it generates the output. This architecture allows the model to process input text in a parallel, rather than sequential, manner, which makes it more efficient and effective than previous models. The transformer architecture has been widely adopted in natural language processing and has been shown to be highly effective for many tasks.
In a transformer, the “attention” mechanism allows the model to focus on different parts of the input text at different times as it generates the output text. This is different from previous neural network models, which processed the input text sequentially, one word at a time. The attention mechanism in a transformer works by calculating a weight for each word in the input text. This weight represents the importance of that word in the context of the current output word that the model is generating. The model then uses these weights to decide which words in the input text to focus on as it generates the output. This allows the model to selectively focus on the most relevant words in the input text.
GPT-2 was announced Feb 2019 by OpenAI, trained on 40GB of text.
GPT-3 was introduced May 2020 and in beta testing in July 2020. Trained on 10x the data, or 400GB.
BERT is a response to GPT and GPT-2 is in turn a response to BERT.
This attention concept looks akin to a fourier or laplace transform which encodes the entire input signal in a lossless manner in a way that allows sections or bands of it to be referred to later. Although implemented differently it’s a way to keep track of and refer to global state.
BERT and GPT are both based on the Transformer ideas. BERT is bidirectional and better at ccomprehending meaning from the whole sentence/phrase whereas GPT is better at generating text.
“The most important distinguishing feature of this approach from the basic encoder–decoder is that it does not attempt to encode a whole input sentence into a single fixed-length vector. Instead, it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. This frees a neural translation model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector. We show this allows a model to cope better with long sentences.”
This description makes it more like a wavelet transform, that does auto-correleations of a signal at different levels of granularity to make sense of it.
Conceptual progression
Input -> Encoder -> Decoder -> Output
Encoder maintains Hidden States to parse/grok the input. These are vectors. Once it goes through the input, it passes the final Hidden State, called the Context forward to the Decoder.
This Context is the bottleneck in the operation of the Decoder.
The Attention concept introduced by Bahdanau and others was to overcome the bottleneck in the Context
With Attention the entire set of intermediate Hidden states is passed on to the Decoder, not just the final Context.
The Decoder does a couple additional steps than before. a) it assigns a score assigned to each Hidden state b) it multiplies the Hidden state with the score. This set of scored vectors are then passed on to the Decoder to produce the Output.
Omnisci is a columnar database that reads a column into GPU memory, in compressed form, allowing for interactive queries on the data. A single gpu can load 10million to 50million rows of data and allows interactive querying without indexing. A demo was shown at the GTC keynote this year, by Aaron Williams. He gave a talk on vehicle analytics that I attended last month.
In the vehicle telemetry demo, they obtain vehicle telemetry data from an F1 game that has data output as UDP, 10s of thousands of packets a second – take the binary data off of UDP, and convert it to json and use it as a proxy for real telemetry data. The webserver refreshes every 3-4 seconds. The use case is analysis of increasing amounts of vehicle sensor data as discussed in this video and described in the detailed Omnisci blog post here.
Programming of the blocks is done through the UX with StreamSets which is an open source tool to build data pipelines – a cool demo of streamsets for creating pipelines including kafka is here.
The vehicle analytics demo pipeline consisted of UDP to Kafka, Kafka to JSON, then JSON to OmniSci via pymapd . Kafka serves as a message broker and also for playback of data.
Based on the the GPU loaded data, the database allows queries and stats on different vehicles that are running.
The entire system runs in the cloud on a VM supporting Nvidia GPUs, and can also be run on a local GPU box.
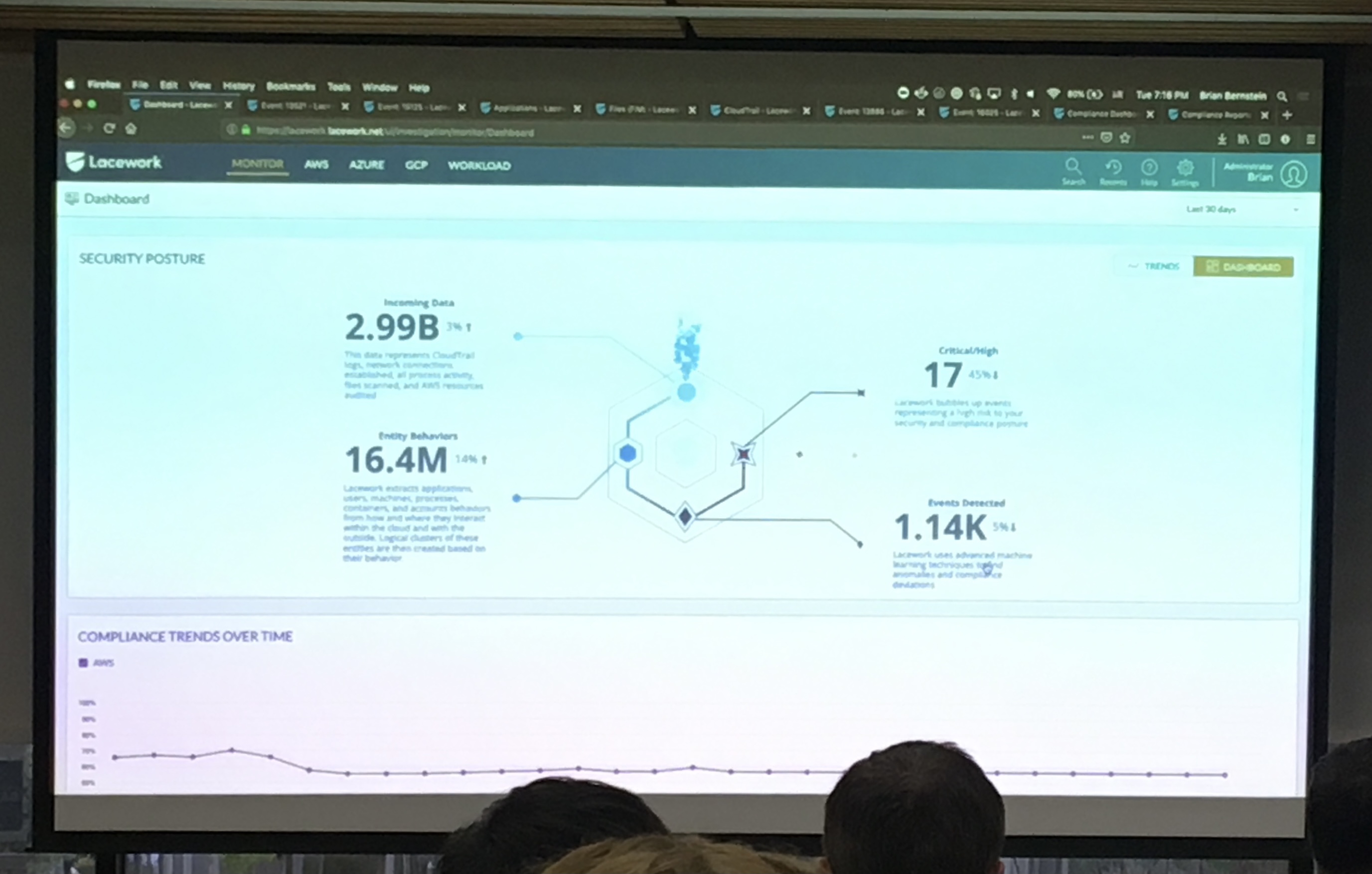
Lacework Polygraph is a Host based IDS for cloud workloads. It provides a graphical view of who did what on which system, reducing the time for root cause analysis for anomalies in system behaviors. It can analyze workloads on AWS, Azure and GCP.
It installs a lightweight agent on each target system which aggregates information from processes running on the system into a centralized customer specific (MT) data warehouse (Snowflake on AWS) and then analyzes the information using machine learning to generate behavioral profiles and then looks for anomalies from the baseline profile. The design allows automating analysis of common attack scenarios using ssh, privilege changes, unauthorized access to files.
The host based model gives detailed process information such as which process talked to which other and over what api. This info is not available to a network IDS. The behavior profiles reduce the false positive rates. The graphical view is useful to drill down into incidents.
It does not have an intrusion prevention (IPS) functionality. False positives on an IPS could block network/host access and negatively affect the system being protected, so it’s a harder problem.
Cloud based network isolation tools like Aviatrix might make IPS scenarios feasible by limiting the effect of an IPS.
There are a number of tools used to detect security issues in a software application codebase. A simple and free one is flawfinder. A sophisticated commercial one is Veracode. There’s also lint, pylint, findbugs for java, and xcode clang static analyzer.
Synopsis has bought a few tools like Coverity and Blackduck for various static checks on code and binary. Blackduck can do binary analysis and scores issues with the CVSS. A common use of Blackduck is for license checking to check for conformance to open source licenses.
A more comprehensive list of static code analysis tools is here.
Dynamic analysis tools inspect the running process and find memory and execution errors. Well known examples are valgrind and Purify. More dynamic tools are listed here.
A common issue with the tools is the issue of false positives. It helps to limit the testing to certain defect types or attack scenarios and identify the most critical issues, then expand the scope of types of defects.
Code obfuscation and anti-tamper are another line of tools, for example by Arxan, Klocwork, Irdeto and Proguard .
A great talk on Adventures in fuzzing. My takeaway has been that better ways of developing secure software are really important.
As a developer Apple made it the transition from TouchId to FaceId easy with the LocalAuthentication library (more below). But as a user that had grown accustomed to TouchId, I did not like the TouchId button going away. What were the reasons for TouchId to be replaced completely by FaceId. What happened on other platforms like Android and FIDO ? Let’s explore in this post.
Both Touch ID and Face ID are biometric authentication technologies developed by Apple for their iPhone lineup. Each has distinct implementations and security features. Here’s a detailed contrast of the security aspects and implementations of Touch ID and Face ID:
Touch ID
Implementation:
Technology: Touch ID uses a capacitive touch sensor embedded in the Home button or, in newer models, in the power button.
Enrollment: Users register their fingerprint by repeatedly placing their finger on the sensor, which captures a high-resolution image of the fingerprint.
Authentication: When authenticating, the sensor captures the fingerprint image and compares it to the enrolled fingerprint data.
Security Features:
Secure Enclave: Fingerprint data is stored in an encrypted format in the Secure Enclave, a separate processor within the iPhone’s A-series chip. This ensures that fingerprint data is never accessible to the operating system or any apps.
False Acceptance Rate (FAR): Apple claims that the chance of a random person being able to unlock an iPhone with Touch ID is approximately 1 in 50,000.
Liveness Detection: Touch ID includes some measures to detect the presence of a live finger to prevent spoofing with artificial fingerprints.
Face ID
Implementation:
Technology: Face ID uses a combination of infrared and dot projection technology, known as the TrueDepth camera system, to create a detailed 3D map of the user’s face.
Enrollment: Users enroll by moving their head around so that the TrueDepth camera can capture their face from multiple angles.
Authentication: During authentication, the system projects over 30,000 infrared dots onto the user’s face and captures the pattern with an infrared camera to create a 3D facial map.
Security Features:
Secure Enclave: Facial data is also stored in the Secure Enclave in an encrypted format, similar to Touch ID, ensuring it is never accessible to the operating system or apps.
False Acceptance Rate (FAR): Apple claims that the probability of a random person unlocking an iPhone with Face ID is approximately 1 in 1,000,000.
Liveness Detection: Face ID employs advanced liveness detection to ensure the person presenting the face is real and not a photo or mask. This includes attention awareness, requiring the user’s eyes to be open and looking at the device.
Adaptability: Face ID can adapt to changes in the user’s appearance over time, such as growing facial hair, wearing glasses, or aging.
Comparison and Security Implications
Accuracy and False Acceptance Rate: Face ID is significantly more accurate than Touch ID, with a FAR of 1 in 1,000,000 compared to Touch ID’s 1 in 50,000. This means Face ID is generally more secure against random attempts to unlock the device.
Resistance to Spoofing: Both systems are designed to resist spoofing, but Face ID’s use of 3D facial mapping and infrared technology makes it more robust against attempts to bypass it using photos or masks. Touch ID’s liveness detection is less sophisticated compared to Face ID.
Environmental Conditions: Touch ID can be affected by wet or dirty fingers and may not work if the sensor is damaged. Face ID, on the other hand, can be impacted by certain lighting conditions or if the user is wearing accessories that obscure the face (e.g., certain sunglasses or masks).
User Convenience: Face ID generally offers a more seamless experience as it works even when the user’s hands are occupied or when wearing gloves. However, in situations where face coverings are required, Touch ID may be more convenient.
Both Touch ID and Face ID offer robust security features, but Face ID provides enhanced security through its more sophisticated technology and lower false acceptance rate. The choice between the two may come down to personal preference and specific use cases, such as the need for convenience in different environments.
Transition from Touch ID to Face ID
API Transition:
Initial Introduction:
Touch ID (iOS 7, 2013): When Apple introduced Touch ID with the iPhone 5s, they provided APIs in the LocalAuthentication framework, allowing developers to integrate fingerprint authentication into their apps.
Face ID (iOS 11, 2017): With the introduction of Face ID in the iPhone X, Apple updated the LocalAuthentication framework to support facial recognition alongside fingerprint recognition.
Unified API:
Apple designed the LocalAuthentication framework to abstract away the specifics of biometric authentication. This means developers typically don’t need to change their code to support both Touch ID and Face ID. Instead, they use general methods to request biometric authentication, and the system handles the specifics.
For example, the method LAContext.evaluatePolicy(_:localizedReason:reply:) works for both Touch ID and Face ID.
Backward Compatibility:
Apple ensured backward compatibility, so apps built to support Touch ID automatically support Face ID without requiring significant changes. The system dynamically determines which biometric method to use based on the hardware capabilities of the device.
Developer Considerations:
Developers are encouraged to check for biometric type (LABiometryType) to provide appropriate messaging or handle specific cases where one type may be preferred.
Apple provides clear guidelines and updates during WWDC (Apple Worldwide Developers Conference) to help developers transition smoothly and take full advantage of new hardware features.
FIDO on Android
FIDO (Fast Identity Online):
Overview:
The FIDO Alliance is an open industry association aimed at creating authentication standards to reduce reliance on passwords. FIDO protocols use standard public key cryptography techniques to provide stronger authentication.
Adoption on Android:
Android has supported FIDO2 since Android 7.0 (Nougat). FIDO2 includes WebAuthn (web authentication API) and CTAP (Client to Authenticator Protocol), enabling passwordless authentication on the web and mobile apps.
Google Play Services provide FIDO2 API support, making it available on most modern Android devices.
Biometric Integration:
Android’s BiometricPrompt API (introduced in Android 9.0 Pie) allows apps to integrate various types of biometric authentication (fingerprint, face, iris) in a standardized way.
BiometricPrompt is designed to support multiple biometric types, providing a unified API similar to Apple’s LocalAuthentication framework.
Face ID on Android:
Face Authentication:
Android supports face authentication through the BiometricPrompt API. The specifics of face authentication can vary by manufacturer, as Android devices have diverse hardware capabilities.
Devices like Google Pixel 4 and some Samsung models have advanced face recognition similar to Apple’s Face ID, using infrared sensors and dot projection for 3D facial mapping.
FIDO and Biometric Standards:
The FIDO Alliance promotes biometric standards, including facial recognition, but the implementation and quality can vary widely on Android devices.
Some Android manufacturers implement their own facial recognition solutions, while others rely on Google’s BiometricPrompt API for a more standardized approach.
Transition from Touch ID to Face ID:
Apple’s transition from Touch ID to Face ID was facilitated by a unified API (LocalAuthentication), allowing seamless integration for developers and users.
FIDO on Android:
FIDO2 standards are widely supported on Android, enabling strong, passwordless authentication.
Android supports multiple biometric methods, including facial recognition, through the BiometricPrompt API. However, the implementation quality and technology can vary between devices.
OCP has the mission to “design and enable the delivery of the most efficient server, storage and data center hardware designs for scalable computing”.
OCP had its global 2019 summit recently. Some interesting trends on hyperscale networks are discussed here and here with the use of F16 fabric network with its a focus on higher bandwidth but also performance at the right cost instead of at any cost. The heart of this new F16 fabric is the Minipack switch, with contribution from Arista which Facebook says will consume 50 percent less power and space than the Backpack switch it replaces in the network. It is a 128x100Gb switch and uses a Broadcom Tomahawk-3 Asic. Quote: “a path from a rack in one building to a rack in another building over Fabric Aggregator was as many as 24 hops long before. With F16, same-fabric network paths are always the best case of six hops, and building-to-building flows always take eight hops. This results in half the number of intrafabric network hops and one-third the number of interfabric network hops between servers.”
Intel announced an industry collaboration around Platform Root of Trust at the Open Compute Project 2019 summit.
There’s a talk on Stratum and the use of P4 and Switch Abstraction Interface (SAI) for SDN, by Open Networking Foundation (ONF) and Google. Tencent has a use case for disaggregating their monolithic network into a modular switch with a network of controllers instead of a single controller.
Smaller data centers at the edge is another trend.
Facebook storage stack and its evolution- https://thenewstack.io/facebook-storage/, mentions OCP and the disaggregated server model which separates server components across different racks.
This error often occurs after another checkin has gone in before yours, and says “the tip of your current branch is behind its remote counterpart”.
It should be resolved by
a) ‘git pull –rebase’ // this may bring in conflicts that need to be resolved
followed by
b) ‘git push’ // this works the first time
After the two steps your changes are available to team members to code review and you may need to edit your changes. After making such changes, you’d need to do