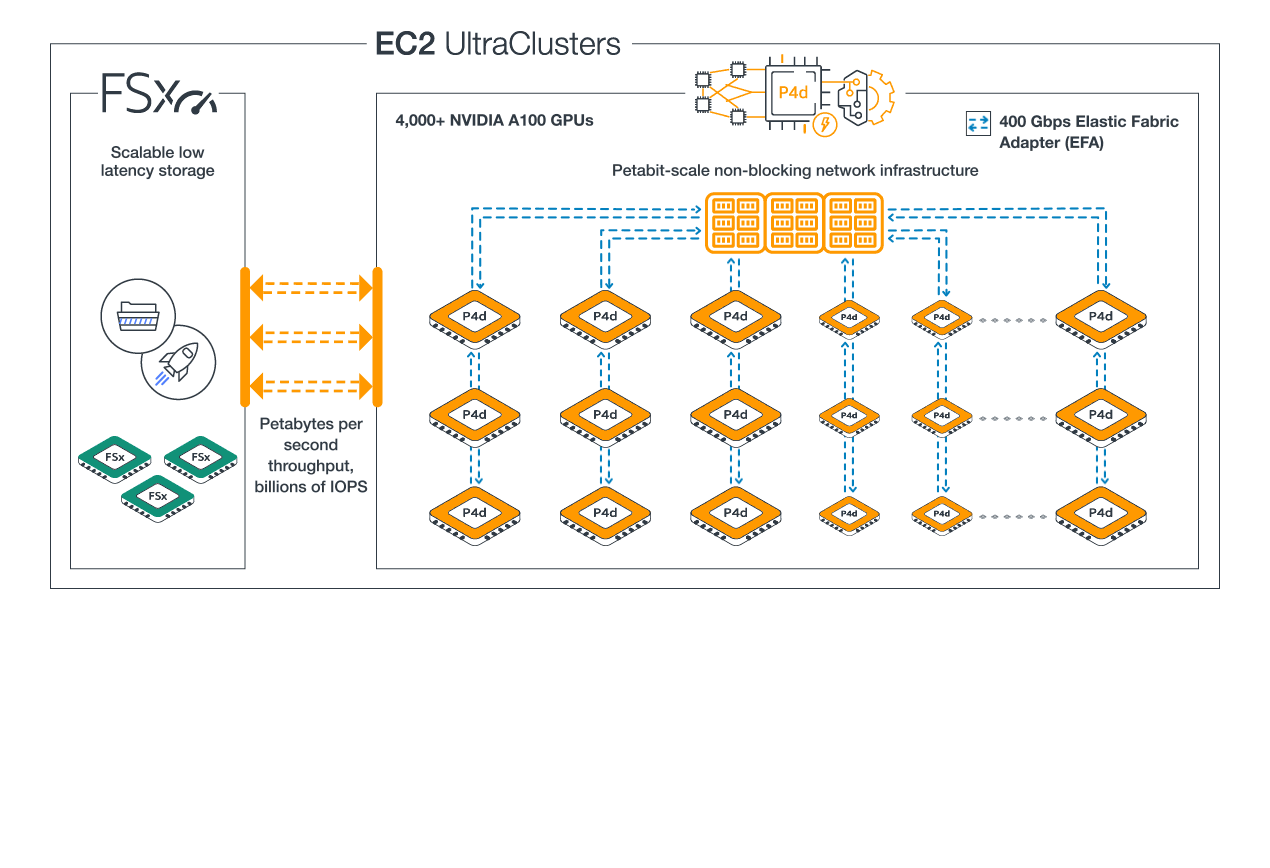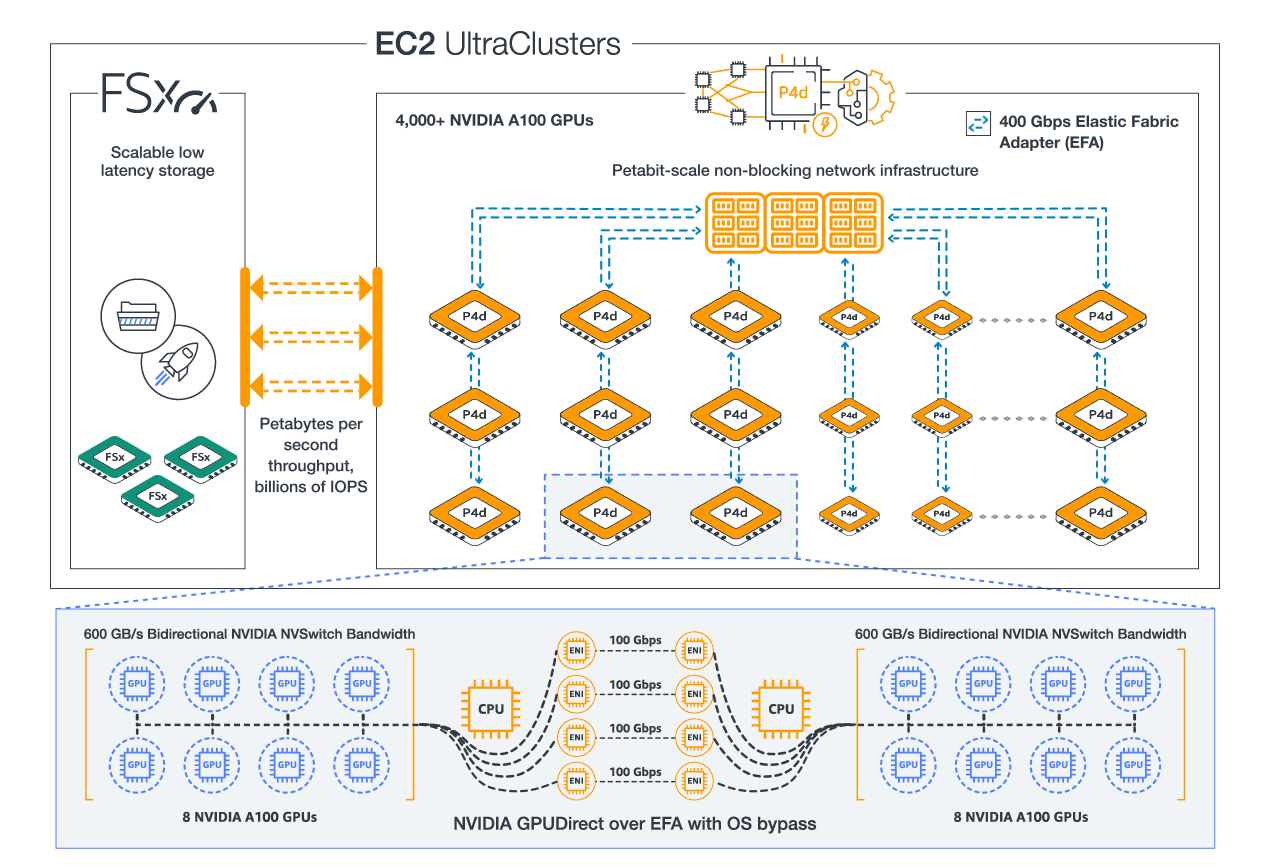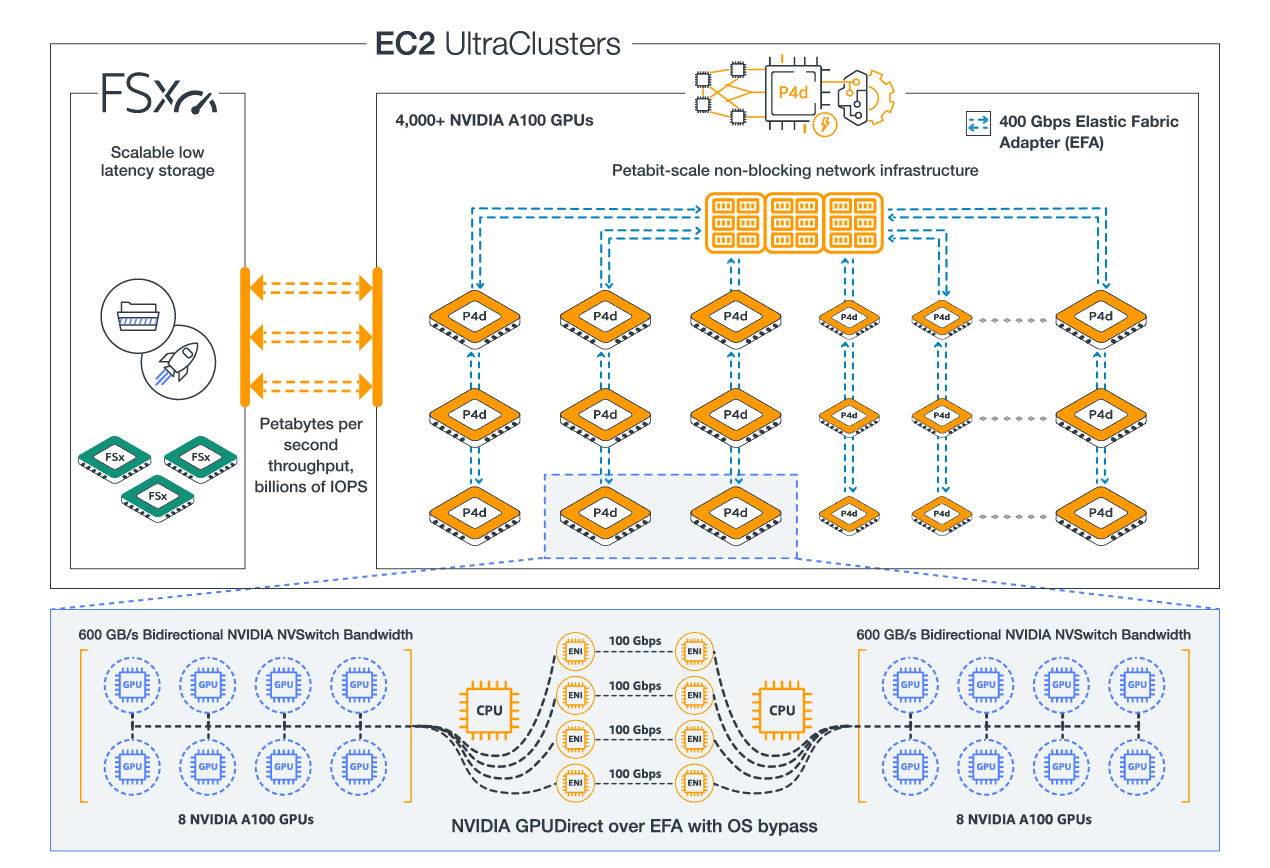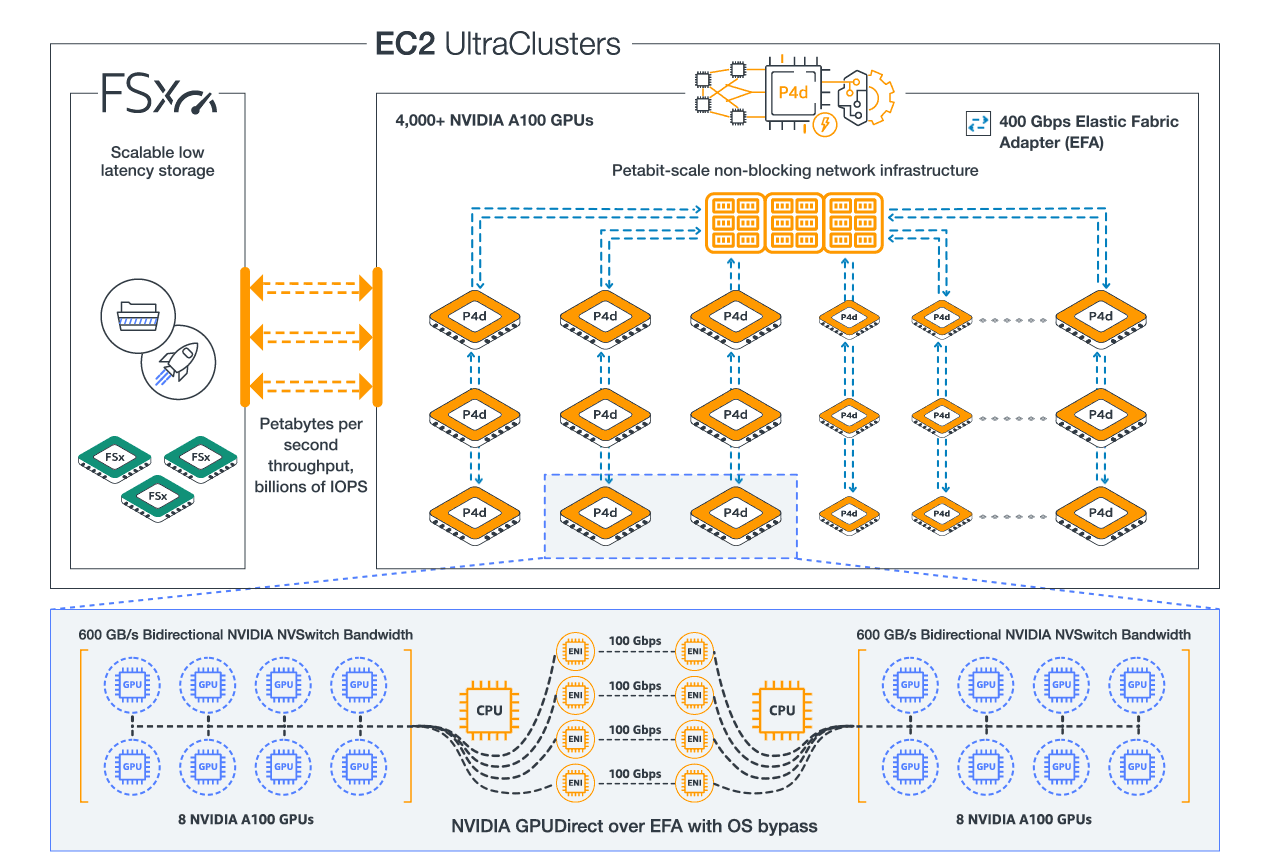
When choosing the EC2 instance for a Large Language Model, one of the first constraints is whether the model will fit in the GPU memory of an instance.
Given a choice of a model, the decisions roughly follow this path –
Model -> Training/Inferencing -> Technique (choice of optimization) -> Memory requirement -> Instance requirement -> Instance availability -> smaller instance or more optimization or distributed training.
Some extreme optimizations are possible such as QLora for Inferencing . See the blog How to fit a layer in memory at a time https://huggingface.co/blog/lyogavin/airllm . However many use cases do not want any sacrifices in accuracy.
Distributed training by splitting the model against smaller instances is another possibility. A discussion is here – https://siboehm.com/articles/22/pipeline-parallel-training
Here’s a listing of different GPU instance types with a column for GPU Memory (GiB) on one page to facilitate instance comparisons.
EC2 G3 Instance Details
| Name | GPUs | vCPU | Memory (GiB) | GPU Memory (GiB) | Price/hr* (Linux) | Price/hr* (Windows) | 1-yr Reserved Instance Effective Hourly* (Linux) | 3-yr Reserved Instance Effective Hourly* (Linux) |
|---|---|---|---|---|---|---|---|---|
| g3s.xlarge | 1 | 4 | 30.5 | 8 | $0.75 | $0.93 | $0.525 | $0.405 |
| g3.4xlarge | 1 | 16 | 122 | 8 | $1.14 | $1.876 | $0.741 | $0.538 |
| g3.8xlarge | 2 | 32 | 244 | 16 | $2.28 | $3.752 | $1.482 | $1.076 |
| g3.16xlarge | 4 | 64 | 488 | 32 | $4.56 | $7.504 | $2.964 | $2.152 |
EC2 G4 Instance details
| Instance Size | GPU | vCPUs | Memory (GiB) | Instance Storage (GB) | Network Bandwidth (Gbps) | EBS Bandwidth (Gbps) | On-Demand Price/hr* | 1-yr Reserved Instance Effective Hourly* (Linux) | 3-yr Reserved Instance Effective Hourly* (Linux) | |
G4dn | ||||||||||
| Single GPU VMs | g4dn.xlarge | 1 | 4 | 16 | 1 x 125 NVMe SSD | Up to 25 | Up to 3.5 | $0.526 | $0.316 | $0.210 |
| g4dn.2xlarge | 1 | 8 | 32 | 1 x 225 NVMe SSD | Up to 25 | Up to 3.5 | $0.752 | $0.452 | $0.300 | |
| g4dn.4xlarge | 1 | 16 | 64 | 1 x 225 NVMe SSD | Up to 25 | 4.75 | $1.204 | $0.722 | $0.482 | |
| g4dn.8xlarge | 1 | 32 | 128 | 1 x 900 NVMe SSD | 50 | 9.5 | $2.176 | $1.306 | $0.870 | |
| g4dn.16xlarge | 1 | 64 | 256 | 1 x 900 NVMe SSD | 50 | 9.5 | $4.352 | $2.612 | $1.740 | |
| Multi GPU VMs | g4dn.12xlarge | 4 | 48 | 192 | 1 x 900 NVMe SSD | 50 | 9.5 | $3.912 | $2.348 | $1.564 |
| g4dn.metal | 8 | 96 | 384 | 2 x 900 NVMe SSD | 100 | 19 | $7.824 | $4.694 | $3.130 | |
G4ad | ||||||||||
| Single GPU VMs | g4ad.xlarge | 1 | 4 | 16 | 1 x 150 NVMe SSD | Up to 10 | Up to 3 | $0.379 | $0.227 | $0.178 |
| g4ad.2xlarge | 1 | 8 | 32 | 1 x 300 NVMe SSD | Up to 10 | Up to 3 | $0.541 | $0.325 | $0.254 | |
| g4ad.4xlarge | 1 | 16 | 64 | 1 x 600 NVMe SSD | Up to 10 | Up to 3 | $0.867 | $0.520 | $0.405 | |
| Multi GPU VMs | g4ad.8xlarge | 2 | 32 | 128 | 1 x 1200 NVMe SSD | 15 | 3 | $1.734 | $1.040 | $0.810 |
| g4ad.16xlarge | 4 | 64 | 256 | 1 x 2400 NVMe SSD | 25 | 6 | $3.468 | $2.081 | $1.619 | |
EC2 G5 instance details
| Instance Size | GPU | GPU Memory (GiB) | vCPUs | Memory (GiB) | Storage (GB) | Network Bandwidth (Gbps) | EBS Bandwidth (Gbps) | On Demand Price/hr* | 1-yr ISP Effective Hourly (Linux) | 3-yr ISP Effective Hourly (Linux) | |
| Single GPU VMs | g5.xlarge | 1 | 24 | 4 | 16 | 1×250 | Up to 10 | Up to 3.5 | $1.006 | $0.604 | $0.402 |
| g5.2xlarge | 1 | 24 | 8 | 32 | 1×450 | Up to 10 | Up to 3.5 | $1.212 | $0.727 | $0.485 | |
| g5.4xlarge | 1 | 24 | 16 | 64 | 1×600 | Up to 25 | 8 | $1.624 | $0.974 | $0.650 | |
| g5.8xlarge | 1 | 24 | 32 | 128 | 1×900 | 25 | 16 | $2.448 | $1.469 | $0.979 | |
| g5.16xlarge | 1 | 24 | 64 | 256 | 1×1900 | 25 | 16 | $4.096 | $2.458 | $1.638 | |
| Multi GPU VMs | g5.12xlarge | 4 | 96 | 48 | 192 | 1×3800 | 40 | 16 | $5.672 | $3.403 | $2.269 |
| g5.24xlarge | 4 | 96 | 96 | 384 | 1×3800 | 50 | 19 | $8.144 | $4.886 | $3.258 | |
| g5.48xlarge | 8 | 192 | 192 | 768 | 2×3800 | 100 | 19 | $16.288 | $9.773 | $6.515 |
EC2 G6 instance details
| Instance Size | GPU | GPU Memory (GB) | vCPUs | Memory (GiB) | Storage (GB) | Network Bandwidth (Gbps) | EBS Bandwidth (Gbps) | On Demand Price/hr* | 1-yr ISP Effective Hourly (Linux) | 3-yr ISP Effective Hourly (Linux) | |
| Single GPU VMs | g6.xlarge | 1 | 24 | 4 | 16 | 1×250 | Up to 10 | Up to 5 | $0.805 | $0.499 | $0.342 |
| g6.2xlarge | 1 | 24 | 8 | 32 | 1×450 | Up to 10 | Up to 5 | $0.978 | $0.606 | $0.416 | |
| g6.4xlarge | 1 | 24 | 16 | 64 | 1×600 | Up to 25 | 8 | $1.323 | $0.820 | $0.562 | |
| g6.8xlarge | 1 | 24 | 32 | 128 | 2×450 | 25 | 16 | $2.014 | $1.249 | $0.856 | |
| g6.16xlarge | 1 | 24 | 64 | 256 | 2×940 | 25 | 20 | $3.397 | $2.106 | $1.443 | |
| Gr6 instances with 1:8 vCPU:RAM ratio | |||||||||||
| gr6.4xlarge | 1 | 24 | 16 | 128 | 1×600 | Up to 25 | 8 | $1.539 | $0.954 | $0.654 | |
| gr6.8xlarge | 1 | 24 | 32 | 256 | 2×450 | 25 | 16 | $2.446 | $1.517 | $1.040 | |
| Multi GPU VMs | g6.12xlarge | 4 | 96 | 48 | 192 | 4×940 | 40 | 20 | $4.602 | $2.853 | $1.955 |
| g6.24xlarge | 4 | 96 | 96 | 384 | 4×940 | 50 | 30 | $6.675 | $4.139 | $2.837 | |
| g6.48xlarge | 8 | 192 | 192 | 768 | 8×940 | 100 | 60 | $13.35 | $8.277 | $5.674 | |
EC2 G6e instances
| Instance Size | GPU | GPU Memory (GiB) | vCPUs | Memory(GiB) | Storage (GB) | Network Bandwidth (Gbps) | EBS Bandwidth (Gbps) |
| g6e.xlarge | 1 | 48 | 4 | 32 | 250 | Up to 20 | Up to 5 |
| g6e.2xlarge | 1 | 48 | 8 | 64 | 450 | Up to 20 | Up to 5 |
| g6e.4xlarge | 1 | 48 | 16 | 128 | 600 | 20 | 8 |
| g6e.8xlarge | 1 | 48 | 32 | 256 | 900 | 25 | 16 |
| g6e.16xlarge | 1 | 48 | 64 | 512 | 1900 | 35 | 20 |
| g6e.12xlarge | 4 | 192 | 48 | 384 | 3800 | 100 | 20 |
| g6e.24xlarge | 4 | 192 | 96 | 768 | 3800 | 200 | 30 |
| g6e.48xlarge | 8 | 384 | 192 | 1536 | 7600 | 400 | 60 |
EC2 P3 instance details
| Instance Size | GPUs – Tesla V100 | GPU Peer to Peer | GPU Memory (GB) | vCPUs | Memory (GB) | Network Bandwidth | EBS Bandwidth | On-Demand Price/hr* | 1-yr Reserved Instance Effective Hourly* | 3-yr Reserved Instance Effective Hourly* |
|---|---|---|---|---|---|---|---|---|---|---|
| p3.2xlarge | 1 | N/A | 16 | 8 | 61 | Up to 10 Gbps | 1.5 Gbps | $3.06 | $1.99 | $1.05 |
| p3.8xlarge | 4 | NVLink | 64 | 32 | 244 | 10 Gbps | 7 Gbps | $12.24 | $7.96 | $4.19 |
| p3.16xlarge | 8 | NVLink | 128 | 64 | 488 | 25 Gbps | 14 Gbps | $24.48 | $15.91 | $8.39 |
| p3dn.24xlarge | 8 | NVLink | 256 | 96 | 768 | 100 Gbps | 19 Gbps | $31.218 | $18.30 | $9.64 |
EC2 P4 instance details
| Instance Size | vCPUs | Instance Memory (GiB) | GPU – A100 | GPU memory | Network Bandwidth (Gbps) | GPUDirect RDMA | GPU Peer to Peer | Instance Storage (GB) | EBS Bandwidth (Gbps) | On-demand Price/hr | 1-yr Reserved Instance Effective Hourly * | 3-yr Reserved Instance Effective Hourly * |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p4d.24xlarge | 96 | 1152 | 8 | 320 GB HBM2 | 400 ENA and EFA | Yes | 600 GB/s NVSwitch | 8 x 1000 NVMe SSD | 19 | $32.77 | $19.22 | $11.57 |
| p4de.24xlarge (preview) | 96 | 1152 | 8 | 640 GB HBM2e | 400 ENA and EFA | Yes | 600 GB/s NVSwitch | 8 x 1000 NVMe SSD | 19 | $40.96 | $24.01 | $14.46 |
EC2 P5 instance details
| Instance Size | vCPU | Instance Memory (TiB) | GPU – H100 | GPU Memory | Network Bandwidth | GPUDirectRDMA | GPU Peer to Peer | Instance Storage (TB) | EBS Bandwidth (Gbps) |
| p5.48xlarge | 192 | 2 | 8 | 640 GB HBM3 | 3200 Gbps EFAv2 | Yes | 900 GB/s NVSwitch | 8 x 3.84 NVMe SSD | 80 |
EC2 P5e instance details
| Instance Size | vCPUs | Instance Memory (TiB) | GPU | GPU memory | Network Bandwidth (Gbps) | GPUDirect RDMA | GPU Peer to Peer | Instance Storage (TB) | EBS Bandwidth (Gbps) |
| p5e.48xlarge | 192 | 2 | 8 x NVIDIA H200 | 1128 GB HBM3e | 3200 Gbps EFA | Yes | 900 GB/s NVSwitch | 8 x 3.84 NVMe SSD | 80 |
Relevant links
P5e and P5en announcement (update Sep’24). https://aws.amazon.com/blogs/machine-learning/amazon-ec2-p5e-instances-are-generally-available/
https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units
Use of Triton and NIM to make use of GPU memory across multiple GPUs on an instance –
https://github.com/aws-samples/amazon-eks-machine-learning-with-terraform-and-kubeflow
https://aws.amazon.com/blogs/hpc/deploying-generative-ai-applications-with-nvidia-nims-on-amazon-eks
FP4 and four bit integer quantization, and QLoRA
Note: Performance is not just about GPU memory but also network bandwidth which is needed to load the large models especially for a platform serving multiple models.
When comparing the importance of high memory bandwidth between training and inference for Large Language Models (LLMs), it is generally more critical for training. Here’s why:
1. Training LLMs
- Data Movement: Training LLMs involves frequent data movement between the GPU memory and the processing units. Each training iteration requires loading large batches of data, performing extensive matrix multiplications, and updating weights, all of which are memory-intensive operations.
- Backward Pass: During the training phase, the backward pass (gradient computation and backpropagation) is highly memory bandwidth-intensive. The gradients of each layer are computed and propagated back through the network, requiring significant memory access.
- Parameter Updates: High memory bandwidth is essential to handle the large volume of data being read and written during the parameter updates across multiple layers, especially in very deep models.
- Larger Models and Datasets: Training large models like GPT-3 or GPT-4 involves massive datasets and millions (or even billions) of parameters, leading to a substantial demand for memory bandwidth.
2. Inferencing of LLMs:
- Data Movement: During inference, the primary task is to process input data and generate outputs, which involves reading the model parameters and performing computations. While this still requires good memory bandwidth, the demands are generally lower compared to training.
- No Backpropagation: Inference does not involve the backward pass or parameter updates, significantly reducing the need for continuous memory writes. The absence of gradient computations and updates reduces the overall memory bandwidth requirements.
- Smaller Batch Sizes: Inference typically operates on smaller batch sizes compared to training, further reducing the demand for memory bandwidth.
- Optimizations: Techniques such as model quantization and optimized inference runtimes (like TensorRT) can reduce the memory bandwidth required during inference by optimizing how data is accessed and processed.